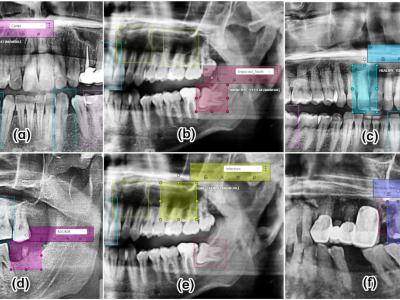
Defect pattern recognition (DPR) of wafer maps is critical for determining the root cause of production defects, which can provide insights for the yield improvement in wafer foundries. During wafer fabrication, several types of defects can be coupled together in a piece of wafer, it is called mixed-type defects DPR. To detect mixed-type defects is much more complicated because the combination of defects may vary a lot, from the type of defects, position, angle, number of defects, etc. Deep learning methods have been a good choice for complex pattern recognition problems.
- Categories: