*.csv

A synthetic laser reliability dataset generated using generative adversarial networks (GANs) is provided. The data includes normalized current measurements estimated at the following times: 2, 20, 40, 60, 80, 100, 150, 500, 1000, and 1500 hours. The data can be used to train machine learning models to solve different predictive maintenance tasks such as prediction of performance degradation, remainng useful prediction, and so on.
- Categories:
 148 Views
148 Views
The dataset contains labeled sentences. The sentences having information related to (1) infections, (2) suffering from pneumonea, (3) deaths, and (4) health updates from government/WHO, are labeled with 1 and the rest are labeled with 0. Source of all the news articles: https://www.thehindu.com/archive/
- Categories:
130 Views
Outdoor temperature data collected by taxis in Rome, Italy.
This dataset is to be used in conjunction with the roma/taxi dataset and provides the outdoor temperature of the areas in Rome where the taxis were located (289 taxicabs over 4 days).
date/time of measurement start: 2012-08-15
date/time of measurement end: 2014-02-04
- Categories:
622 Views
This dataset provides wireless measurements from two industrial testbeds: iV2V (industrial Vehicle-to-Vehicle) and iV2I+ (industrial Vehicular-to-Infrastructure plus sensor).
iV2V covers 10h of sidelink communication scenarios between 3 Automated Guided Vehicles (AGVs), while iV2I+ was conducted for around 16h at an industrial site where an autonomous cleaning robot is connected to a private cellular network.
- Categories:
2683 Views
Mobile networks have become highly complex systems. In order to better understand how network features affect performance and suggest additional improvements, it is crucial to examine them from an empirical perspective.
- Categories:
2680 Views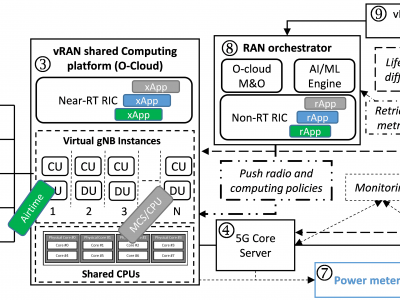
The Open Radio Access Network (O-RAN) Alliance's most recent innovations are propelling the evolution of RAN deployments, moving away from conventionally closed and specialized hardware implementations and toward virtualized instances running over shared platforms and distinguished by open interfaces. Such progressive decoupling of radio software components from the hardware is paving the road for future efficient and cost-effective RAN deployments. However, there are still a lot of open challenges before O-RAN networks can be successfully deployed.
- Categories:
4484 Views
This dataset serves as the Geolocation Database for TV White Space. The dataset contains channel information and availability data. The channel information has the following columns: CHANNEL, COMPANY_NAME, DIGITAL, CALLSIGN, LATITUDE, LONGITUDE, LOWER_BAND, UPPER_BAND, TX_FREQ, ERP, TX_PWR. CHANNEL refers to the channel used, expressed in CH + channel number. COMPANY_NAME is the company name of the primary user. DIGITAL has a value of 1 when it use a digital transmission, otherwise it has a value of 0. CALLSIGN is the callsign of the primary user.
- Categories:
81 Views
Here we provide the dataset containing the power measurements obtained with our RIS prototype, which were carried out in the anechoic chamber of TU Darmstadt.
The use of data here contained is intended only for research purposes.
- Categories:
450 Views
Sign languages are the most common mode of communication with and between hearing-impaired individuals. In the Arab world, Arabic sign language is used with different dialects supporting a distinct set of rules for the gestures used. With research on natural language processing advancing, models have been developed to translate sign language to spoken language and vice versa. However, Arabic sign language has rarely been studied due to the lack of availability of datasets dealing with Arabic sign language.
- Categories:
2035 Views
The dataset was collected by performing uplink/downlink throughput measurements in Munich, Germany. The user side device was a vehicle with roof-mounted antenna (approx. 1.5 m height), and on the network side was a base station antenna mounted at the top of a building (height of the antenna with respect to the ground: 21 m). The measurements were collected at the center frequency of 3.41 GHz, with 40 MHz of bandwidth, with antenna gain of 15.5dBi (5dBi) at the base station (vehicle) side. The maximum throughput in the uplink was 40 Mbps.
- Categories:
704 Views