Other

An improved coupled mode theory, grounded in the field matching technique, has been devised and validated for photonic devices with gradually varying structures, such as tapers. This novel approach addresses a limitation of traditional coupled mode theory, which approximates varying structures by dividing them into several uniform sections with different waveguide widths. This segmentation often leads to unphysical field reflections at the interfaces between adjacent sections, impacting both power propagation and reflection coefficients of the devices.
- Categories:
 35 Views
35 Views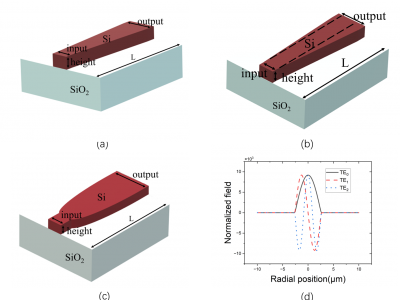
(a) The 3D structural dimensions, refractive index distribution, and related parameters of the linear taper. (b) The corresponding 3D structure and refractive index distribution of the asymmetric taper. (c) The corresponding 3D structure and refractive index distribution of the parabolic taper. (d) The normalized electric field distribution in the cross-sectional direction, including TE0, TE1, and TE2 modes.
- Categories:
52 Views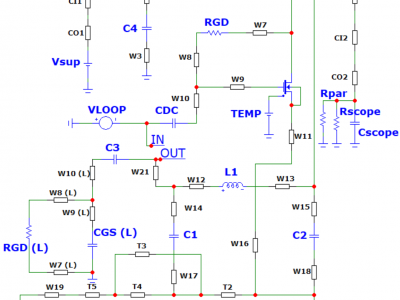
This dataset describes the measured or calculated values of most components shown in the Dataset Image. These components were used to accurately model a Pierce oscillator circuit for RT operation. Each bond wire (W1, W2, etc.) is represented by a series resistance and inductance placed parallel with a capacitor, all calculated based upon the length of the wire. Each inconel and standard coaxial cable (CI1-2 and CO1-2) is represented with the same three components.
- Categories:
126 Views
A crucial requirement for effective human-AI teaming is the ability to form mutually compatible mental models that help humans discern when the AI can be relied upon and how to best complement each other. To understand the impact of having this mutual understanding, we conducted an experiment where participants (N=125), tasked as disaster relief planners, were assisted by an AI agent that recommends optimal allocation of a resource based on several information sources. The interaction effects of mental models between the human and the AI were studied.
- Categories:
81 Views
Electrical Impedance Tomography system measures change in path conductivity of a cross section of ROI. ROI is created by surrounding a cross-section by metal electrodes. These inject microlevel charges into ROI and attenuation due to ROI material is reconstructed.
X-ray CT is a well known non destructive imaging technology used primarily in medical applications. However, industrial CT are used for industrial applciations.
Computational Fluid dynamics assist flow simulation of fluid channels.
- Categories:
283 Views
This dataset comprises Bloomberg Terminal data from 2017 to 2021, detailing environmental footprints, disclosure practices, risk profiles, and ESG fund commitments of Fortune 500 companies. The data captures various dimensions of environmental, social, and governance (ESG) performance, providing a comprehensive view of corporate sustainability trends. It includes quantitative indicators and qualitative scores for companies' ESG strategies, enabling researchers to analyze ESG practices and trends over time.
- Categories:
178 Views
Benchmark code, HPC runtime logs, and analysis for the "AcceleratedKernels.jl: Cross-Architecture Parallel Algorithms from a Unified, Transpiled Codebase" Paper.
- Categories:
30 Views
This dataset package includes four datasets, of which Dataset 1 is Mackey-Glass chaotic time series and Dataset 2 is monthly sunspot numbers data. Both Dataset 1 and Dataset 2 are datasets with periodic characteristics. Dataset 3 is daily foreign exchange rates and Dataset 4 is daily gold price. Both Dataset 3 and Dataset 4 are financial data.
- Categories:
98 Views
The data set is based on the elevation mapping of HI-TARGET's iHand55 device and the processing of existing pipeline information.The data is mainly used for pipeline drainage or urban drainage planning and design test.This data is the drainage system data of a city, including drainage points and drainage pipeline information.
- Categories:
33 Views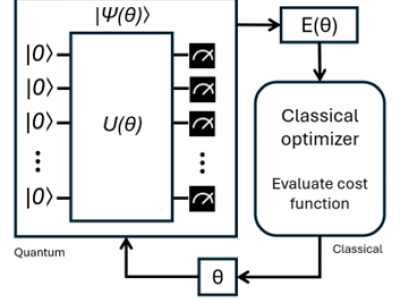
As quantum computing advances, there is a growing need for sophisticated computational methods that efficiently leverage quantum resources. This paper investigates the integration of adaptive quantum circuits with the Variational Quantum Eigensolver (VQE) algorithm, proposing Adaptive VQE as an enhanced approach for dynamically constructing quantum ansätze.
- Categories:
176 Views