Other

This paper presents a Tube-based Robust Model Predictive Control (Tube-RMPC) strategy for autonomous vehicle control, designed to address model parameter uncertainties and variations in road-tire adhesion coefficients under complex driving conditions. The proposed approach enhances the representation of vehicle dynamics by introducing a unified vehicle-tire modeling framework, capturing nonlinear characteristics more effectively.
- Categories:
 24 Views
24 Views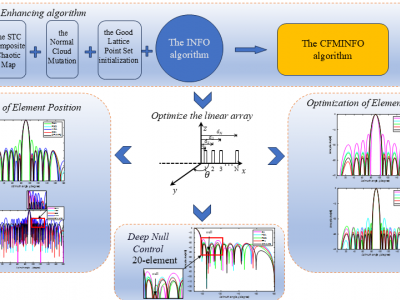
Abstract—This manuscript introduces the Chaos Fusion Mutation INFO algorithm (CFMINFO), which integrates multiple strategies and updates vector positions through three core processes. These processes incorporate Good Point Set initialization, Sine-Tent-Cosine (STC) chaotic parameterization, and Normal Cloud Mutation strategies. The algorithm is characterized by its simplicity, rapid convergence, and ability to avoid local optima. To validate its performance, CFMINFO is applied to the optimization of linear arrays.
- Categories:
104 Views
The dataset contains a revised version of the psychophysical color difference Munsell Re-renotation dataset.
Munsell Re-renotation is a psychophysical dataset describing large color differences, featuring 2986 colors characterized by standard colorimetric coordinates (x, y, Y) and coordinates within the Munsell system (H, V, C).The Munsell Re-renotation iteration enhances the uniformity of the system compared to its predecessor, the Munsell Renotation dataset.
- Categories:
41 Views
Transformers, especially dry-type transformers, which nowadays are going to be employed instead of oil-type transformers, are one of the major equipment in the generation, transmission and distribution network of electric energy. The transformer insulation strength may reduce due to partial discharge (PD) occurrence, and this can finally result in its insulation failure.
- Categories:
15 Views
- Categories:
25 Views
The attached zip contains both data and analysis scripts for the first two particle-in-cell examples in the associated paper. In particular,
(1) The BeamExpansion folder contains output z vs r phase space data from the quasi-Helmholtz FEMPIC code used in the paper at 3 ns (fempic.csv), as well as the equivalent data from an XOOPIC simulation (xoopic.txt). The analysis is done in the ipython notebook file in the folder. All of the plots in the paper was generated using this same script.
- Categories:
51 Views
This is the multimedia of the paper “Bearing-based collision-free formation control for spacecrafts under dynamic event-triggered input”, including datasets (in .xlsx format), presentations (in .pptx format), and illustrative videos.
- Categories:
29 Views
# ! Disclaimer!
- Add jar dependencies to build path : ( ~/OCLDependencies.zip, ~/ModiscoDependencies.zip, ~/PapyrusDependencies.zip).
- For evosuite : add dependencies to the pom file :
https://www.evosuite.org/documentation/maven-plugin/
# Content:
1. TSE co-evolution zip file :
* (data v1) folder : includes 10 projects that was used for the evaluation process, before the metamodel evolution, containing the generated tests.
- Categories:
28 Views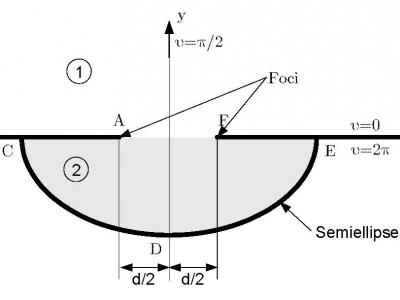
We have developed exact analytical solutions of new canonical electromagnetic scattering problems. These new analytical solutions provide benchmarks for the validation of computational electromagnetic software.
- Categories:
102 Views
We have developed exact analytical solutions of new canonical electromagnetic scattering problems. These new analytical solutions provide benchmarks for the validation of computational electromagnetic software.
- Categories:
86 Views