Other

In this work, an ultrathin plasma-enhanced atomic layer deposition (PEALD) alumina (Al2O3) was first introduced between top platinum (Pt) and underneath a-IZO. As consistently verified by experiment and simulation, such interlayer fundamentally eradicate the interface oxygen deficiency and MIGS, contributing to a much higher ΦB and noticeably JR, while the optimized ultrathin thickness readily allow the electron tunneling, resulting in minimal impact on the forward current.
- Categories:
 19 Views
19 Views
This benchmark set consists of real-world industrial instances that incorporate long bit-wise optimizations and are primarily composed of datapath circuits, including adders and multipliers. It includes 8 instances in total, which can be categorized into three distinct levels of difficulty. All instances are represented as miter circuits in the AIG format, designed to compare two functionally equivalent circuits for testing purposes.
- Categories:
122 Views
The dataset were compiled and obtained using the HarmonyERP (https://www.harmonyerp.cloud/en/) software used by KNS Otomotiv (www.knsotomotiv.com/en/) which operates with the ATO model. The KNS company produces parts in various categories such as air duct systems, service sets, continuous LED lighting systems, grab bars, and baskets for commercial vehicles (buses).
- Categories:
71 Views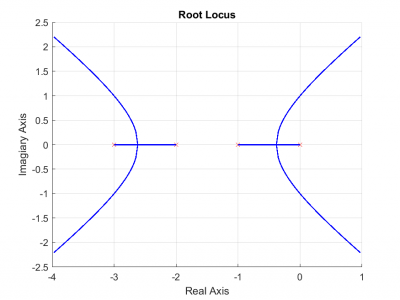
A new rootlocus algorithm is proposed for the construction of the root locus of dynamic systems. The “rootlocus.m” function implements the proposed algorithm. The “rootlocus.m” function takes as input the numerator “Num” and the denominator “Den” of the loop gain function characterizing the considered dynamic system. The user may also provide a third input “kk”, which is the vector containing the desired values for the control parameter “K” of the feedback system. If not provided, a default choice is assumed for vector containg the values for the control parameter “K”.
- Categories:
124 Views
Set5, Set11, and Set14 are classic small-scale benchmark datasets widely used for image super-resolution tasks. BSD100 and BSD500 feature complex natural scenes, commonly used for denoising and segmentation research. McM18 is a medical imaging dataset focused on medical image reconstruction. Urban100 emphasizes urban scenes, ideal for evaluating models on high-frequency details and structural textures. These datasets span diverse applications, serving as valuable benchmarks in computer vision research.
- Categories:
25 Views
Laboratory measurements and simulations of Multiconductor Transmission Lines ended in electronic components. There are datasets corresponding to the following cases:
- one-wire transmission line ended in a diode
- one-wire transmission line ended in an op-amp
- two-wire transmission line where one of the wires is ended in an op-amp (cross-talk study), the other excited by either sin or a square pulse
- Categories:
23 Views
This dataset was generated using high-fidelity air combat simulations to develop and evaluate Weapon Engagement Zone (WEZ) prediction models. It contains data for various Beyond Visual Range (BVR) air combat scenarios, capturing diverse conditions and configurations between a shooter aircraft and a target.
The dataset is split into factorial and random design datasets, with outputs representing critical WEZ parameters, including the maximum range (Rmax) and the no-escape zone (Rnez).
- Categories:
61 Views
This dataset contains survey responses collected from Agile practitioners across various roles, including Scrum Masters, Developers, Product Owners, and Agile Coaches, from organizations with diverse Agile practices. The survey aimed to identify the common challenges in backlog refinement, such as time constraints, prioritization issues, and ambiguous user stories. It also explored perceptions of Generative AI's role in streamlining Agile workflows, enhancing productivity, and reducing cognitive load.
- Categories:
81 Views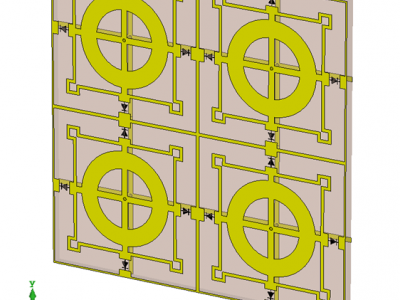
This paper presents a low-profile, dual-stopband active frequency selective surface (AFSS) with an ultra-wide band ratio (BR) to overcome the limited tuning range and suboptimal profile of current designs. The proposed design consists of a periodic pattern printed on the top of a thin substrate and a bias network on the bottom, with varactor diodes symmetrically mounted on the top metal layer. Based on the equivalent circuit model, the mechanism of wideband tuning is analyzed theoretically.
- Categories:
62 Views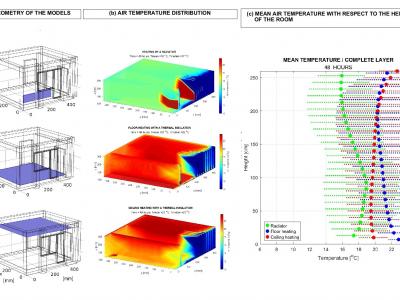
Numerical simulations are used to assess the efficiency of floor heating, ceiling heating, and plane radiator heating in a selected family house room under winter conditions in the Central European climate zone. COMSOL Multiphysics software was used for computer simulations. The output data were subsequently processed and analyzed using MATLAB software. Results indicate that floor and ceiling heating systems achieve higher and more rapid temperature increases compared to plane radiators.
- Categories:
162 Views