Other

This is the dataset for "An Efficiently Updatable Path Oracle for Terrain Surfaces" submitted to IEEE Transactions on Knowledge and Data Engineering. For more details, please refer to our code GitHub link https://github.com/yanyinzhao/UpdatedStructureTerrainCode.
- Categories:
 164 Views
164 Views
Normal 0 0 2 false false false EN-US JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:標準の表; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0mm 5.4pt 0mm 5.4pt; mso-para-margin:0mm; mso-pagination:widow-orphan; font-size:10.5pt; mso-bidi-font-size:11.0pt; font-family:"游明朝",serif; mso-ascii-font-family:游明朝; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:游明朝; mso-fareast-theme-font:minor-fareast; mso-hansi-font-family:游明朝; mso-hansi-theme-font:minor-latin; mso-font-kerning:
- Categories:
470 Views
A duobinary transmitter has been realized in this paper. The combination of high-frequency compensation characteristics of 6-tap feed forward equalizer (FFE) and high frequency attenuation characteristics of FR4 backplane is used to produce duobinary signal. 5-stage calibrated delay unit with source capacitance degeneration is used to achieve a delay of 100 ps.
- Categories:
26 Views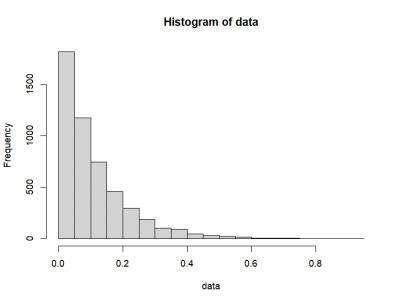
This dataset consists of a simulated exponential distribution data, featuring n=5000n = 5000n=5000 data points, each generated with a rate parameter of 9. The exponential distribution is commonly used to model the time between events in a Poisson process, where the rate parameter indicates the average number of events occurring in a unit of time. In this case, the relatively high rate parameter of 9 suggests that events are expected to happen frequently.
- Categories:
640 Views
Given the non-cooperative relationship between the transmitter and the jammer, two main challenges are addressed in this paper: how to model their interactions and how to devise a jamming strategy without prior knowledge of the transmitter. A non-zero-sum game is used to model and analyze such non-cooperative interactions. An approximate mixed-strategy Nash equilibrium (NE) under complete information is derived to serve as a benchmark for comparison.
- Categories:
85 Views
The REST (REpresentational State Transfer) paradigm has become essential for designing distributed applications that leverage the HTTP protocol, enabling efficient data exchange and the development of scalable architectures such as microservices. However, selecting an appropriate framework among the myriad available options, especially given the diversity of emerging execution environments, presents a significant challenge. Often, this decision neglects crucial factors such as performance and energy efficiency, favoring instead developer familiarity and popularity within the industry.
- Categories:
385 Views
This study proposes a stabilization approach when applying $N$th-order compensation for the average consensus of a multi-agent system affected by non-uniform, asymmetric, and time-varying delays in a communication network.
A continuous-time linear dynamical system with a local discrete-time controller modeled for each agent.
In our previous study, we proposed a packet selection algorithm that always selects the most recent packet and a synchronization algorithm that compensates for asymmetric delays to achieve an average consensus considering first-order compensation.
- Categories:
27 Views
Most existing graph keyword search works assume that the graph data is complete and clean, that is, there are no missing information (such as keywords or edges) and contaminated information (such as keywords) on the graph. However, real-world graphs often suffer from missing or being contaminated, making the keyword search on graphs much more challenging. We provide this dataset for the keyword search on dirty graphs.
- Categories:
69 Views
Normal
0
0
2
false
false
false
EN-US
JA
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:標準の表;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0mm 5.4pt 0mm 5.4pt;
mso-para-margin:0mm;
mso-pagination:widow-orphan;
font-size:10.0pt;
font-family:"Times New Roman",serif;
mso-fareast-language:EN-US;}
- Categories:
402 Views
Electrical Impedance Tomography system measures change in path conductivity of a cross section of ROI. ROI is created by surrounding a cross-section by metal electrodes. These inject microlevel charges into ROI and attenuation due to ROI material is reconstructed.
X-ray CT is a well known non destructive imaging technology used primarily in medical applications. However, industrial CT are used for industrial applciations.
Computational Fluid dynamics assist flow simulation of fluid channels.
- Categories:
95 Views