Machine Learning

The dataset used was derived from a frequency tunable high power vacuum electron devices (HPVED) optimization task using a simple genetic algorithm (SGA). This device has the topology with 44 optimization parameters and 2 tuning parameters. Each of the two tuning parameters has 6 and 7 discrete adjustment values, respectively. The population size is set to 54, and each individual requires 42 simulations to evaluate its tunability.
- Categories:
 397 Views
397 Views
Crowdfunding campaigns frequently fail to reach their funding goals, posing a significant challenge for project creators. To address this issue and empower future crowdfunding stakeholders, accurate prediction models are essential. This study evaluates the relative significance of diverse modalities (visual, audio, and text) in predicting campaign success.
- Categories:
191 Views
This dataset contains precomputed MS-COCO and Flickr30K Faster R-CNN image features, which are all the data needed for reproducing the experiments in "Stacked Cross Attention for Image-Text Matching", our ECCV 2018 paper. We use splits produced by Andrej Karpathy.
- Categories:
54 Views
Mulan , a sourceforge net multi-target dataset available in www.openml.org. Despite the numerous interesting applications of MTR, there are only few publicly available datasets of this kind - perhaps because most applications are industrial - and most experimental evaluations of MTR methods are based on a limited amount of datasets. For this study, much effort was made for the composition of a large and diverse collection of benchmark MTR datasets.
- Categories:
355 Views
Ulos is one of the traditional fabrics originating from North Sumatra, Indonesia. Ulos has various motifs and distinctive colors, which reflect the culture and philosophy of the Batak people. In this study, we collected a dataset of color ulos images with high pixel quality. The purpose of this research is to analyze the visual characteristics of ulos, such as pattern, color, and explore the potential utilization of this dataset for various applications, such as cultural preservation, product development, and visual analysis.
- Categories:
127 Views
We developed a unique and valuable dataset specifically for advancing Brain-Computer Interface (BCI) systems by recording brain activity from a dedicated volunteer. The participant was asked to pronounce 100 carefully selected Malayalam words, along with their English translations, which were chosen for their relevance to astronauts during human space missions. The volunteer pronounced these words both vocally and subvocally, each word being repeated 50 times. Non-invasive Electroencephalography (EEG) sensors were employed to capture the brain activity associated with these tasks.
- Categories:
616 Views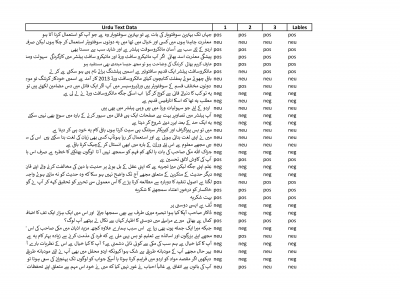
This study used a benchmark dataset, applying different embedding like LASER and FastText to capture contextual information, which was combined to create a new hybrid embedding. This hybrid embedding was fed to machine-learning (ML) and deep learning (DL) classifiers.
- Categories:
280 Views
As the world increasingly becomes more interconnected, the demand for safety and security is ever-increasing, particularly for industrial networks. This has prompted numerous researchers to investigate different methodologies and techniques suitable for intrusion detection systems (IDS) requirements. Over the years, many studies have proposed various solutions in this regard, including signature-based and machine learning (ML)-based systems. More recently, researchers are considering deep learning (DL)-based anomaly detection approaches.
- Categories:
196 Views
Smart grid, an application of Internet of Things (IoT) is modern power grid that encompasses power and communication network from generation to utilization. Home Area Network (HAN), Field or Neighborhood Area Network (FAN/NAN) and Wide Area network (NAN) using Wireless LAN and Wireless/Wired WAN protocols are employed from generation to utilization . Advanced Metering Infrastructure, a utilization side infrastructure facilitates communication between smart meters and the server where energy efficient protocols are mandate to support smart grid .
- Categories:
335 Views
This dataset consists of 737 documents from the BBC Sport website, corresponding to sports news articles in five topical areas from 2004-2005. The class labels are divided into five categories: athletics, cricket, football, rugby, and tennis. The datasets have been pre-processed using the Porter stemming algorithm, stop-word removal, and filtering out terms with low frequency (count < 3).
- Categories:
175 Views