new_data
- Citation Author(s):
-
Muhammad Tariq Javeed (University of Management and Technology, Lahore, Pakistan)
- Submitted by:
- Kashif Ishaq
- Last updated:
- DOI:
- 10.21227/fyrf-wm34
- Data Format:
 293 views
293 views
- Categories:
- Keywords:
Abstract
This study used a benchmark dataset, applying different embedding like LASER and FastText to capture contextual information, which was combined to create a new hybrid embedding. This hybrid embedding was fed to machine-learning (ML) and deep learning (DL) classifiers. ML classifiers consist of three ensembles: bagging utilizes Random Forest (RF), boosting with Light Gradient Boosting Machine (LGBM) and Xtreme Gradient Boosting (XGB), and stacking with Support Vector Machine (SVC) and XGB as base learners and Logistic Regression (LR) as the Meta classifier. DL classifiers such as fully connected network (FCN), Convolutional neural network (CNN), long short-term memory (LSTM), and gated recurrent unit (GRU) have been employed. The model's performance was assessed through independent set and k-fold testing with 5 and 10 folds, using evaluation metrics such as Accuracy, Recall, Precision, and F1 score. In experiments, DL classifiers have outperformed ML classifiers regarding accuracy score. The proposed model outperformed previous benchmark studies, achieving an Accuracy of 0.86, Recall of 0.901, Precision of 0.866, and F1 score of 0.883 in the independent set test. This method contributes to NLP research by showcasing the utility of a hybrid embedding approach.
Instructions:
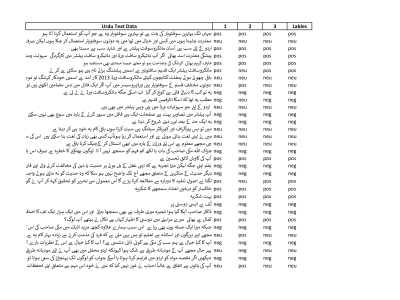
The benchmark dataset, which comprises 10009 tweets for the proposed study, was obtained from Twitter for Urdu sentiment classification. Following a thorough annotation process, the annotators identified about 7,000 sentences that belonged to three classes such as positive, negative, and neutral sentiments. As a result, two classes with both positive and negative sentiments were selected to carry out this investigation, a benchmark dataset was created because of this selection procedure and used in the analysis. The final dataset has 3719 positive Urdu tweets and 2561 negative tweets. The other sentences were left unsettled since they could not be categorically placed into either group.







great work