Image Processing
This is the pest image dataset. With this data set at hand, scientists or software engineers may create programs capable of recognizing when creatures harm farm produce. This breadth extends not only across different plants but also covers many types of bugs like aphids, leafhoppers, beetles , caterpillars etcetera providing a large diverse pool from which one can train models designed to detect pests. Arranging photos by pest species makes it easy for people looking into them understand what they should expect find.
- Categories:
 2257 Views
2257 Views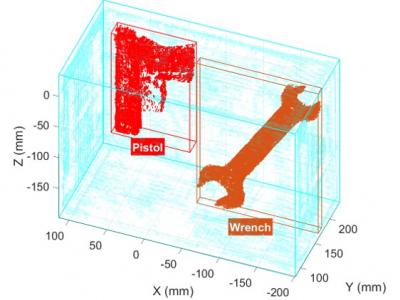
The second set of concealed objects are the pistol and the wrench. The position of the wrench is on the top layer, and the pistol is on the bottom layer. The light blue part is the perimeter of the cardboard box, the red part is the pistol, and the orange part is the wrench. The results of object classification, where the concealed objects are boxed, and the object classification outcomes are displayed beneath the box, all of which are correctly classified.
- Categories:
104 Views
The reconstruction results from four-sided scanning using our previously developed MMW point cloud reconstruction algorithm are illustrated. The light blue part is the perimeter of the cardboard box, the pink part is the scissors, the dark blue part is the knife, and the red part is the hammer. The results show that even though the objects overlap each other, the reconstruction results of four-sided scanning can still get the rough outline of each object, which is unachievable with 2D imaging.
- Categories:
74 Views
One of the Dravidian language spoken majorly by 60 million people in and around Karnataka state of India is known as Kannada. It is one among 22 scheduled languages of India. Kannada langauge is written in Kannada scriptwhich has its traces back from kadamba script (325-550 AD). There are many languages which were used centuries back and aren’t being used currently whereas Kannada is one such language which is used even today for writing official documents and are being taught at schools which means it is going to be for many years.
- Categories:
287 Views
Large-screen 4K TVs (75 inches or larger) are experiencing a surge in popularity, providing unparalleled immersive experiences. Consequently, there has been a significant shift in user behavior towards consuming more video content on TVs. Investigating Quality of Experience (QoE) on large screens is paramount, given its critical role in upgrading the overall satisfaction and user engagement associated with video streaming services.
- Categories:
21 Views
The BirDrone dataset is compiled by aggregating images of small drones and birds sourced from various online datasets. It comprises 2970 high-resolution images (640x640 pixels), each featuring unique backdrops and lighting conditions. This dataset is designed to enhance machine learning models by simulating real-world scenarios.
Dataset Specifications:
- Categories:
1479 Views
Heart diseases are one of the most common types of diseases that have a very high mortality rate. The best method of accurate diagnosis of coronary artery stenosis is angiography, which has few side effects and is relatively expensive. The data of this study were collected from the Philips Allura Xper FD10 angiography machine of the Cath Lab department of Erfan Niayesh Hospital in Tehran from September 1, 2023 to January 1, 2024. 200 angioplasty clips and 200 normal angiography clips were taken from the left and right coronary arteries.
- Categories:
175 Views
Dataset of images of dragon fruit plants, collected from different media and taken from a dragon fruit field in Rio Branco, Brazil, with a total of 600 images classified among 300 photos of sick plants, with fish eyes among others and 300 photos of healthy plants. For many of the photos, a simple smartphone
camera was used to capture the images.
- Categories:
1112 Views
Precise recognition of soybean pods is a crucial need for acquiring phenotypic characteristics, such as the number of productive pods and the quantity of seeds per plant. There exist several techniques for counting seeds, each with their own boundaries. An automated procedure, such as a machine learning algorithm, that takes a image as input and outputs the discrete count of a certain object of interest in the image, canbe used for this type of work.
- Categories:
210 Views
This dataset comprises a diverse array of image files, each captured using either a mobile phone or a camera. The primary subject of these images is experiment reports, reflecting a wide range of experimental scenarios. These images have been taken in various environments, showcasing the flexibility of the dataset in accommodating different shooting conditions. Formatted as JPG documents, the images exhibit variations in size, offering a rich diversity for analysis.
- Categories:
60 Views