Image Processing
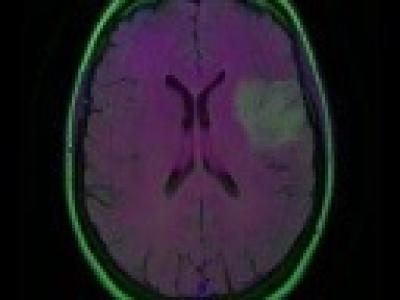
LGG Segmentation Dataset
- Categories:
 923 Views
923 Views
This dataset encapsulates a comprehensive collection of eye movement recordings captured during sleep, exceeding 100 distinct episodes. The recordings are primarily categorized into Rapid Eye Movement (REM), Slow Eye Movement (SEM), and non-movement phases, providing a rich resource for sleep research. Each video is meticulously recorded in high-definition .mp4 format, ensuring clarity and precision in capturing subtle ocular dynamics.
- Categories:
28 Views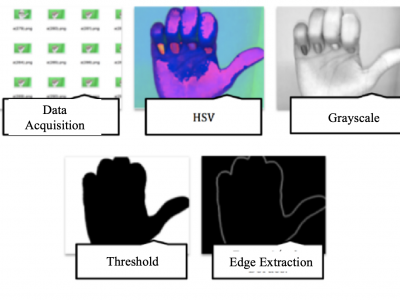
The database presented consists of a set of images of the human hand making signs (20) at various angles, corresponding to the Colombian alphabet of signs established by the National Institute for the Deaf (INSOR). These signs are characterized by being static, that is, they do not require movement to be performed.
- Categories:
215 Views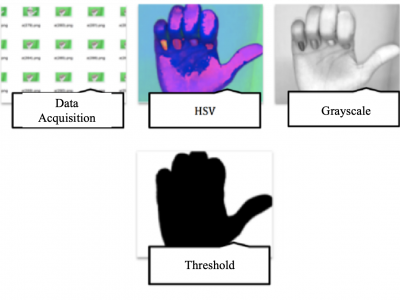
The database presented consists of a set of images of the human hand making signs (20) at various angles, corresponding to the Colombian alphabet of signs established by the National Institute for the Deaf (INSOR). These signs are characterized by being static, that is, they do not require movement to be performed.
- Categories:
157 Views
OpenCL has become the favored framework for emerging heterogeneous devices and FPGAs, owing to its versatility and portability.
However, OpenCL-based math libraries still face challenges in fully leveraging device performance.
When deploying high-performance arithmetic applications on these devices, the most important hot function is General Matrix-matrix Multiplication (GEMM).
This study presents a meticulously optimized OpenCL GEMM kernel.
- Categories:
129 Views
The Deepfake-Synthetic-20K dataset significantly contributes to digital forensics and deepfake detection research. It comprises 20,000 high-resolution, synthetic human face images generated using the advanced StyleGAN-2 architecture. This dataset is designed to support the development and evaluation of machine-learning models that can differentiate between real and artificially synthesized human faces. Each image in the dataset has been meticulously crafted to ensure a diverse representation of age, gender, and ethnicity, reflecting the variability seen in global human populations.
- Categories:
2420 Views
DIRS24.v1 presents a dataset captured in campus environment. These images are curated suitably for the utilization in developing perception modules. These modules can be very well employed in Advanced Driver Assistance Systems (ADAS). The images of dataset are annotated in diversified formats such as COCO-MMDetection, Pascal-VOC, TensorFlow, YOLOv7-PyTorch, YOLOv8-Oriented Bounding Box, and YOLOv9.
- Categories:
602 Views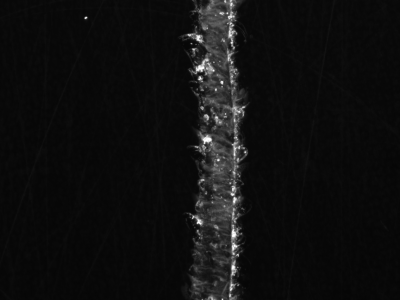
The foundation of detection relies on the surface micro-defect images of KDP, and the effectiveness of the detection model depends on the quality of these images. Higher quality images can pinpoint the shape details and boundary features of defects, thereby enhancing the overall detection capability.
- Categories:
130 Views
As an artificial structure, tailings ponds exhibit regular geometric shapes and relatively straight dams in HRRSIs. Because the typical tailings dam is composed of an initial dam and successive accumulation dams, the tailings dam structure presents obvious linear stripe characteristics. The initial dam, constructed using sand, gravel, or concrete, has a bright color, while the color of the accumulation dam varies based on factors such as particle size, soil coverage, and vegetation restoration.
- Categories:
89 Views
This dataset is used to compressive sensing scenes and assist users in training the optimal sparsity threshold. The input features are image compression ratio, image size, and sparsity, while the label field is the optimal sparsity threshold. The test images are from the USC-SIPI dataset.
- Categories:
40 Views