Artificial Intelligence
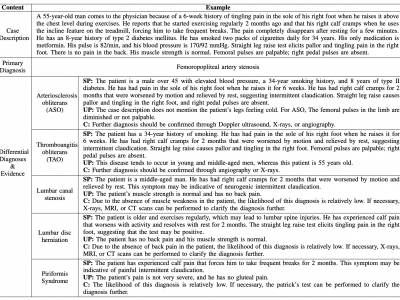
A differential diagnostic (DDX) note generation dataset.
- Categories:
 109 Views
109 Views
Offline-to-online is a key strategy for advancing reinforcement learning towards practical applications. This approach not only reduces the risks and costs associated with online exploration, but also accelerates the agent’s adaptation to real-world environments. It consists of two phases: offline-training and fine-tuning. However, offline-training and fine-tuning have different problems. In offline-training, the main difficulty is how to learn an excellent policy in a limited and incompletely distributed dataset.
- Categories:
74 Views
Since the aircraft trajectory data in the field of air traffic management typically lacks labels, it limits the community's ability to explore classification models. Consequently, evaluations of clustering models often focus on the correctness of cluster assignment rather than merely the closeness within the cluster. To address this, we labeled the dataset for both classification and clustering tasks by referring to aeronautical publications. The process of obtaining the ATFM trajectory dataset consists of data sourcing, preprocessing, and annotation.
- Categories:
140 Views
We used the broad group of 47,692 tweets from the Cyberbullying Classification dataset. This worldwide sourced dataset offers a broad range of examples of cyberbullying, guaranteeing a thorough viewpoint. Our thorough translation and modification procedure guaranteed the dataset's contextual and cultural relevance for the Tamil-speaking population, even though it is not solely from South Asia. These tweets were carefully divided into six classes, each of which represented a different facet of cyberbullying, as well as cases that weren't considered cyberbullying.
- Categories:
369 Views
Text-to-image models, like Midjourney and DALL-E, have been shown to reinforce harmful biases, often perpetuating outdated and discriminatory stereotypes. In this study, we delve into a particularly insidious bias largely overlooked in generative image research: Brilliance Bias. By age six, many children begin to internalize the damaging notion that intellectual brilliance is a male trait—a belief that persists into adulthood. Our findings demonstrate that popular image AI models possess this bias, further entrenching the misguided notion that exceptional intelligence is inherently male.
- Categories:
77 Views
Multimodal sensor fusion has been widely adopted in constructing scene understanding, perception, and planning for intelligent robotic systems. One of the critical tasks in this field is geospatial tracking, i.e., constantly detecting and locating objects moving across a scene. Successful development of multimodal sensor fusion tracking algorithms relies on large multimodal datasets where common modalities exist and are time-aligned, and such datasets are not readily available.
- Categories:
657 Views
Cora, Citeseer, and Pubmed are three citation networks for research papers, where nodes represent publications and edges denote citation links. Node attributes consist of bag-of-words representations of the papers.
ACM is a paper network where nodes represent papers connected by edges if two papers share the same author. The network is characterized by features that include bagof- words representations of paper keywords.
- Categories:
73 Views
This figure shows the accuracy and loss curves generated during the training process. We trained different neural networks on the CIFAR-100 dataset. For each network, the same training strategy was applied to every image in the dataset. The blue curve represents the accuracy after replacing the convolution layers, which achieves a higher accuracy compared to other networks.In the figure, the green curve represents the network after replacing standard convolution with the SCT module.
- Categories:
58 Views
The Theory of Integrated Language Learning (ToILL) supports many complementary schools of educational thought. The constructivism, pragmatism, humanism, and sociocultural theory are combined in one process to produce an integrated and successful method of language acquisition. The approach promotes the complete person development in a continuously changing environment that is global in nature but does not stop at cognitive components but also concerns the social and emotional experiences of the students.
- Categories:
254 Views
The DRIVE dataset, developed by Staal et al. (2004), utilizes the elongated structure of vessel ridges for automatic vessel classification in the Utrecht database. It consists of 40 images (565 × 584 pixels) in JPEG format, captured at a 45° field of view, divided into 20 training and 20 testing images.
- Categories:
46 Views