
Data Description:
- Categories:
Data Description:
This benchmark dataset accompanies an article paper titled ``Learning to Reuse Distractors to support Multiple Choice Question Generation in Education''. It contains a test of 298 educational questions covering multiple subjects & languages and a 77K multilingual pool of distractor vocabulary. The goal is for a given question to propose a list of relevant candidate distractors from the pool of distractors.
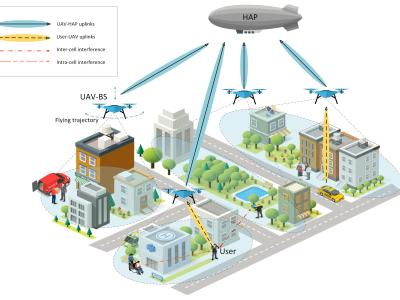
In this paper, we develop a hierarchical aerial computing framework composed of high altitude platform (HAP) and unmanned aerial vehicles (UAVs) to compute the fully offloaded tasks of terrestrial mobile users which are connected through an uplink non-orthogonal multiple access (UL-NOMA).
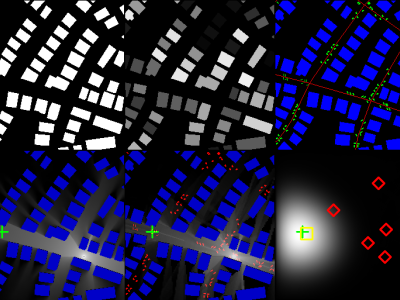
This dataset contains pathloss and ToA radio maps generated by the ray-tracing software WinProp from Altair. The dataset allows to develop and test the accuracies of pathloss radio map estimation methods and localization algorithms based on RSS or ToA in realistic urban scenarios.
The provided dataset is created is created by using European Commission Rapid Alert System's data for Salmonella cases. The dataset composed by 5 variables and all data is providet in categorical format. it is possible to use the dataset predict the salmonella cases based on type of food, month, country and warmth.
# Student Test Results Prediction based on Learning Behavior: Learning Beyond Tests
Dataset Part A: The Goal is to predict Test Results, in the form of averaged correctness, averaged timespent in the test, based only on the learning history (learning behavior records)
Dataset Part B: The objective is to predict the last test results, points and scores, based on the learning behavior records and the first test results.
# About the dataset

In recent years, it has become more difficult to identify road traffic signage and panel guide material. Few studies have been made to solve these two issues at the same time, especially in the Arabic language. Additionally, the limited number of datasets for traffic signs and panel guide content makes the investigation more interesting. the Tunisian research groups in intelligent machines of the University of Sfax (REGIM laboratory of Sfax) will provide the NaSTSArLaT dataset free to researchers in traffic detection signs and traffic road scene text detection.
Transistor models are crucial for circuit simulation. Reliable design of high-performance circuits requires that transistor characteristics are adequately represented, which makes accurate and fast models indispensable. Scattering (or S-)parameters are perhaps the most widely used RF characteristics, employed in the design and analysis of linear devices and circuits for calculation of the input and output impedance, isolation, gain, as well as stability, all being important performance figures for small-signal or low-noise amplifiers.
The dataset includes the device geometries and the corresponding performance. The device geometries consist of four-dimensional factors (L, W, T, H) and the device performance consists of three-dimensional parameters (R, S, δl).

Simultaneously-collected multimodal Mannequin Lying pose (SMaL) dataset is a infant pose dataset based on a posable mannequin. The SMaL dataset contains a set of 300 unique poses under three cover conditions using three sensor modalities: color imaging, depth sensing, and pressure sensing. It represents the first multimodal dataset for infant pose estimation and the first dataset to explore under the cover pose estimation for infants.