large language models
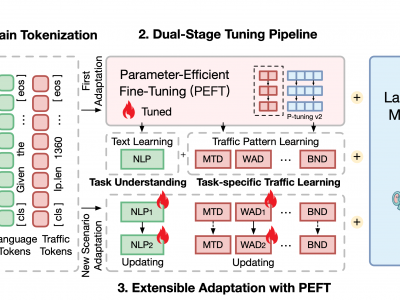
We released TrafficLLM's training datasets, which contain over 0.4M traffic data and 9K human instructions for LLM adaptation across different traffic analysis tasks.
- Categories:
 201 Views
201 Views
Computational experiments within metaverse service ecosystems enable the identification of social risks and governance crises, and the optimization of governance strategies through counterfactual inference to dynamically guide real-world service ecosystem operations. The advent of Large Language Models (LLMs) has empowered LLM-based agents to function as autonomous service entities capable of executing diverse service operations within metaverse ecosystems, thereby facilitating the governance of metaverse service ecosystem with computational experiments.
- Categories:
18 Views
This dataset is constructed in a study that addresses the gap between text summarization and content readability for diverse Turkish-speaking audiences. It contains paired original texts and corresponding summaries optimized for different readability levels using the YOD (Yeni Okunabilirlik Düzeyi) formula.
- Categories:
68 Views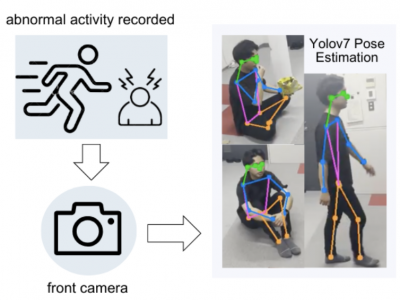
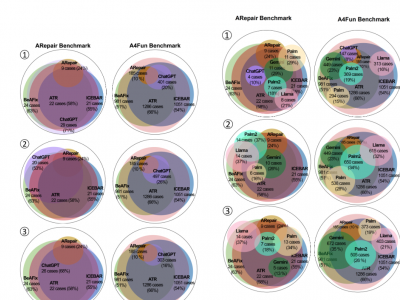
The growing adoption of declarative software specification languages, coupled with their inherent difficulty in debugging, has underscored the need for effective and automated repair techniques applicable to such languages. Researchers have recently explored various methods to automatically repair declarative software specifications, such as template-based repair, feedback-driven iterative repair, and bounded exhaustive approaches. The latest developments in Large Language Models (LLMs) provide new opportunities for the automatic repair of declarative specifications.
- Categories:
231 Views
Code search is essential for code reuse, allowing developers to efficiently locate relevant code snippets. Traditional encoder-based models, however, face challenges with poor generalization and input length limitations. In contrast, decoder-only large language models (LLMs), with their larger size, extensive pre-training, and ability to handle longer inputs, present a promising solution to these issues. However, their effectiveness in code search has not been fully explored.
- Categories:
121 Views
To train critique models capable of delivering step-level supervision and constructive feedback for reasoning, we introduce AutoMathCritique—an automated and scalable framework for collecting critique data.
This framework consists of three main stages: flawed reasoning path construction, critique generation, and data filtering. Using AutoMathCritique, we create a dataset containing $76,321$ samples named MathCritique-76k.
- Categories:
41 Views
CodePromptEval is a dataset of 7072 prompts designed to evaluate five prompt techniques (few-shot, persona, chain-of-thought, function signature, list of packages) and their effect on the correctness, similarity, and quality of complete functions generated. Each data point in the dataset includes a function generation task, a combination of prompt techniques to be applied, the prompt in natural language that applied the prompt techniques, the ground truth of the functions (human-written functions based on CoderEval dataset by Yu et al.), the tests to evaluate the correctness of the generate
- Categories:
31 Views
This dataset comprises over 38,000 seed inputs generated from a range of Large Language Models (LLMs), including ChatGPT-3.5, ChatGPT-4, Claude-Opus, Claude-Instant, and Gemini Pro 1.0, specifically designed for the application in fuzzing Python functions. These seeds were produced as part of a study evaluating the utility of LLMs in automating the creation of effective fuzzing inputs, a method crucial for uncovering software defects in the Python programming environment where traditional methods show limitations.
- Categories:
231 Views