*.csv

Wi-Fi FTM RSSI Localization dataset
Wi-Fi Fine Time Measurement for positioning / Indoor Localization in 3 different locations and using 8 different APs
Custom APs using ESP32C3 and Raw FTM is measured in nanoseconds
Data is only measured at the Router Side
Data is not measured at client side
Has 4 datasets inside the zip folder with over 100,000 data points
Contains processed Wi-Fi FTM packets from various routers in:
- Categories:
 1513 Views
1513 Views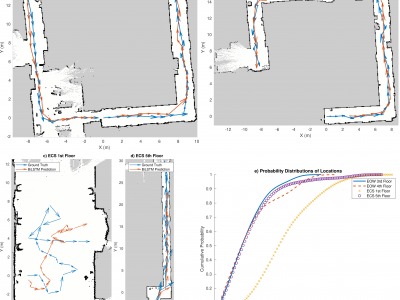
Wi-Fi BLE RSSI SQI Localization dataset
Wi-Fi BLE RSSI for positioning / Indoor Localization in 4 different locations and using 18 different APs
Data is only measured at the Router Side
Data is not measured at client side
Has 12 datasets inside the zip folder with over 1,000,000 data points
- Categories:
991 Views
In today's world of online communication and digital media, hate speech has become an alarming problem worldwide. With the advancement of the internet, while people enjoy numerous benefits, there's also a dark side where individuals are subjected to horrendous bullying through hate speech. Tragically, some instances even lead to extreme actions like suicide or self-destructive behavior.
- Categories:
539 Views
The electroretinogram (ERG) is a clinical test that records the retina's electrical response to light. The ERG is a promising way to study different neurodevelopmental and neurodegenerative disorders, including Autism Spectrum Disorder (ASD) - a neurodevelopmental condition that impacts language, communication, and social interactions. However, privacy issues and a lack of data complicate Artificial Intelligence applications in this domain. Synthetic ERG signals generated from real ERG recordings should carry similar information and could be used as an extension for natural data.
- Categories:
315 Views
The rise of e-commerce in Latin America has been driven by the digital presence of the younger generations and the adaptation of retail businesses to online sales channels. The COVID-19 pandemic has further accelerated this shift, forcing businesses to enhance their online commerce strategies. Peru has witnessed a notable 131\% increase in online shoppers from 2019 to 2021. However, the absence of a unique global code for product identification negatively affects the Zero Moment of Truth (ZMOT) in customer decision-making.
- Categories:
20 Views
The e-commerce market heavily relies on e-coupons, and their digital nature presents challenges in establishing a secure e-coupon infrastructure, which incurs maintenance costs. To address this, we explore using public blockchains for the e-coupon system, providing a highly reliable decentralized infrastructure with no maintenance costs. Storing coupon information on a blockchain ensures tamper resistance and protection against double redemption. However, using public blockchains shifts gas cost responsibility to users, potentially impacting user experience if not managed carefully.
- Categories:
183 Views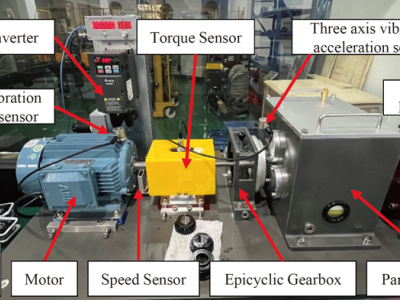
The gearbox is a critical component of electromechanical systems. The occurrence of multiple faults can significantly impact system accuracy and service life. The vibration signal of the gearbox is an effective indicator of its operational status and fault information. However, gearboxes in real industrial settings often operate under variable working conditions, such as varying speeds and loads. It is a significant and challenging research area to complete the gearbox fault diagnosis procedure under varying operating conditions using vibration signals.
- Categories:
1561 Views
Containerization has emerged as a revolutionary technology in the software development and deployment industry. Containers offer a portable and lightweight solution that allows for packaging applications and their dependencies systematically and efficiently. In addition, containers offer faster deployment and near-native performance with isolation and security drawbacks compared to Virtual Machines. To address the security issues, scanning tools that scan containers for preexisting vulnerabilities have been developed, but they suffer from false positives.
- Categories:
91 Views
DataSet used in learning process of the traditional technique's operation, considering different devices and scenarios, perform the commutation through Pure ALOHA protocol, and make the device to operate with the best possible configuration.The control of energy consumption is essential for the operation of battery-operated systems, such as those used in IoT networks and sensors. The algorithms commonly employed for this purpose involve optimization functions with considerable complexity and rigorous control of the test environment.
- Categories:
367 Views
This dataset accompanies a research paper on leveraging Machine Learning (ML) techniques for regression to predict the optimum DC bias in direct current in optical orthogonal frequency division multiplexing (DCO-OFDM). The dataset comprises a set of features to facilitate the prediction of the required DC bias to mitigate the impact of clipping distortion at the transmitter. MATLAB software was utilized for modelling the DCO-OFDM transmission and generating the research dataset.
- Categories:
158 Views