Other
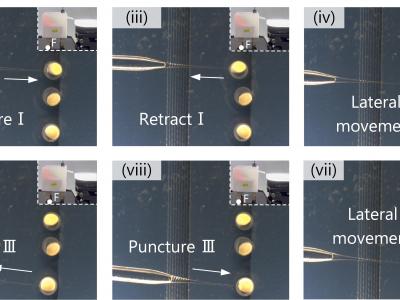
Aself-moving piezoelectric actuator (SMPA) with high carrying/positioning capability is presented in this article. Its Π-shaped mechanical part comprises four piezo-legs, each of which combines the bending vibrations in the first three orders into the motion in the quasi- sawtooth waveform at the driving foot. Besides, a homemade onboard circuit is integrated with the mechanical part to form compact structure.
- Categories:
 69 Views
69 Views
The Big Five Inventory-2 (BFI-2) is one of the most used questionnaires to assess personality traits, distinguishing 15 facets. Despite its usage, there is still room for research to improve its psychometric properties. We applied the Rasch analysis (RA) to transform the BFI-2 into an instrument consisting of actual interval scales (obtaining the BFI-2-R), involving 5362 Italian adults. Five confirmatory factor analyses supported the three-facet structure of each trait. This structure resulted invariant at the scalar level across sex.
- Categories:
211 Views
This dataset, created using FEKO software, serves to investigate the impact of human body blockage on electromagnetic (EM) fields as observed by receiver antennas arranged in dense 2D/3D arrays. The simulation scenario involves an Hertzian dipole emitting radiation at 2.4868 GHz and positioned at a height of 0.99 meters. Field measurements are taken over a 3D array with multiple 2D arrays at varying distances from the source. An anthropomorphic obstacle representing a human body is included, featuring dimensions and material properties based on muscle composition.
- Categories:
115 Views
Scatterplots provide a visual representation of bivariate data (or 2D embeddings of multivariate data) that allows for effective analyses of data dependencies, clusters, trends, and outliers. Unfortunately, classical scatterplots suffer from scalability issues, since growing data sizes eventually lead to overplotting and visual clutter on a screen with a fixed resolution, which hinders the data analysis process. We propose an algorithm that compensates for irregular sample distributions by a smooth transformation of the scatterplot's visual domain.
- Categories:
118 Views
This dataset was obtained from the ionogram at Kupang in 2022 to investigate the frequency window of the Near Vertical Incidence Skywave (NVIS) channel with homogenous Time of Flight (ToF) values. All data is in the form of.mat files (MATLAB). The first dataset is in Matlab variables ('DataWidthFrekHourly','DataCenterWidthFrekHourly'), which consist of maximum window frequency values with homogenous ToF and the center frequency of the widest window. The structure of the data array is 96x365, with the row as the time (1:96) and the column as the day in one year (1:365).
- Categories:
66 Views
To access this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/doi/10.5281/zenodo.11711229
Please cite the following paper when using this dataset:
- Categories:
1018 Views
This is the supplementary document for the review paper titled “Comprehensive and Data-Driven Literature Review of Supernumerary Robotic Limbs,” which presents a comprehensive and data-driven review that offers a quantitative analysis of Supernumerary Robotic Limbs (SRLs), covering application areas, structural designs, control strategies, embodiments, and their interconnections.
- Categories:
175 Views
A craniometry study was undertaken to obtain anthropometric measurements of three hundred and five (305) medical staff within Trinidad & Tobago which is a twin island republic situated in the Caribbean. A non-contact measurement method was used involving 3D scanning equipment to record the geometry of each subject’s head as a digital file. The digital files were then processed using CAD software to obtain measurements for twenty-two (22) facial points of interest. In addition, the gender of each staff member was recorded.
- Categories:
255 Views
MS-BioGraphs are a family of sequence similarity graph datasets with up to 2.5 trillion edges. The graphs are weighted edges and presented in compressed WebGraph format. The dataset include symmetric and asymmetric graphs. The largest graph has been created by matching sequences in Metaclust dataset with 1.7 billion sequences. These real-world graph dataset are useful for measuring contributions in High-Performance Computing and High-Performance Graph Processing.
- Categories:
767 Views
The Cora dataset consists of 2708 scientific publications classified into one of seven classes. The citation network consists of 5429 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1433 unique words.
- Categories:
965 Views