Artificial Intelligence

We construct the Thyroid Nodule Ultrasound (TNUS) dataset with thyroid nodule positions and puncture annotations, lacking in existing datasets. It supports future research in automating detection and diagnosis, enhancing diagnostic accuracy and clinical applications. The TNUS dataset is a curated collection of thyroid nodule ultrasound (US) images designed to support research in puncture position detection and nodule segmentation. It contains 4,376 images with puncture position annotations and 2,626 additional images with thyroid/nodule masks.
- Categories:
 217 Views
217 Views
ÛThis article examines Meta-AI's sociolinguistic challenges on WhatsApp through research-based analysis of its limitations in adapting lexicon and precise ethical practices in intercultural communication. The study demonstrates how Meta-AI system fails to read truncated vernacular speech patterns (“kenapa” → “enapa”) while missing customized slang (“puki”) used specifically in Maluku, North Maluku and East Nusa Tenggara regions to show fundamental limitations in error recognition capabilities and contextual understanding.
- Categories:
113 Views
The BNS (Bharatiya Nyay Sanhita) dataset is a comprehensive collection of legal texts which was web-scraped.. It consists of chapters and their respective sections, capturing detailed legal content relevant to the recently introduced BNS framework in India. This dataset was gathered using a Python-based web scraping script leveraging Selenium WebDriver, ensuring accuracy and completeness. Available in CSV formats, the dataset facilitates ease of access for legal research, natural language processing (NLP) tasks, and AI-based legal assistance applications.
- Categories:
193 Views
This is the patent data we collected from USTPO. Its part of the paper that we used for our study. It contains patent data regarding financial, assistive, and artificial intelligence technology convergence. These patents are all registered in USPTO (united states patent and trademark office) from 2001 to 2020. These data were used for network analysis. Further details will be uploaded after paper acception.
- Categories:
10 Views
Dataset was created for the purposes of exploring time distortion with non-ideal near-field conditions. A 90 Hz square wave is played at 100dBA through a bookshelf speaker with the port removed. The recordings were captured at 5 separate axial distances (From 2" to 17", following inverse square law), and at three levels of resistive loading (No added resistance, 1.5 ohm, 3 ohm). The DC resistance of the speaker was measured at 6.9 ohms. To avoid overtraining, captures were recorded on a moving dynamic microphone.
- Categories:
13 Views
Integrating multiple (sub-)systems is essential to create advanced Information Systems. Difficulties mainly arise when integrating dynamic environments, e.g., the integration at design time of not yet existing services. This has been traditionally addressed using a registry that provides the API documentation of the endpoints.
- Categories:
24 Views
Gramatika is a syntectic GEC dataset for Indonesian. The Gramatika dataset has a total of 1.5 million sentences with 4,666,185 errors. Of all sentences, only 30,000 (2%) are correct sentences with no mistakes. Each sentence has a maximum of 6 errors, and there can only be 2 of the same error type in each sentence.We also split the dataset into three splits: train, dev, and test splits, with the proportion of 8:1:1 (with the size of 1,199,705, 150,171, and 150,124 sentences, respectively).
- Categories:
20 Views
Gramatika is a syntectic GEC dataset for Indonesian. The Gramatika dataset has a total of 1.5 million sentences with 4,666,185 errors. Of all sentences, only 30,000 (2%) are correct sentences with no mistakes. Each sentence has a maximum of 6 errors, and there can only be 2 of the same error type in each sentence.We also split the dataset into three splits: train, dev, and test splits, with the proportion of 8:1:1 (with the size of 1,199,705, 150,171, and 150,124 sentences, respectively).
- Categories:
5 Views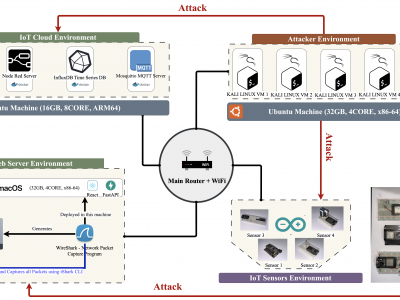
This paper presents an enhanced methodology for network anomaly detection in Industrial IoT (IIoT) systems using advanced data aggregation and Mutual Information (MI)-based feature selection. The focus is on transforming raw network traffic into meaningful, aggregated forms that capture crucial temporal and statistical patterns. A refined set of 150 features including unique IP counts, TCP acknowledgment patterns, and ICMP sequence ratios was identified using MI to enhance detection accuracy.
- Categories:
582 Views
This dataset is specifically designed for the recognition and localization of electric vehicle (EV) charging ports using point cloud data, rather than traditional image-based methods. It includes raw point cloud data collected from advanced sensing technologies such as LiDAR or depth cameras, along with detailed experimental records that encompass sensor parameters, pose annotations, and environmental variables.
- Categories:
151 Views