Artificial Intelligence

The rapid diffusion and steep concentration gradients of ship exhaust plumes create substantial challenges in velocity field estimation and quantification. To address this limitation, this study develops FluentFluid, the first large-scale optical flow dataset specifically designed for plume motion analysis, as a standardized training benchmark. A novel deep optical flow network architecture guided by grayscale attention mechanisms is proposed. The architecture adopts a dual enhancement strategy through Effective Grayscale Pixels (EGPs) and Grayscale Attention Weights.
- Categories:
 4 Views
4 Views
To establish comprehensive training data for fluid optical flow estimation, we developed a simulated ship emission dataset called FluentFluid. This dataset was generated through computational fluid dynamics simulations using ANSYS Fluent software, with focus on ship exhaust plume modeling. The synthesis pipeline began with the construction of a physical model of ship stack exhaust systems, followed by fluid motion simulation under controlled parametric variations, including exit velocity, stack position, turbulence intensity, and ambient wind conditions.
- Categories:
Views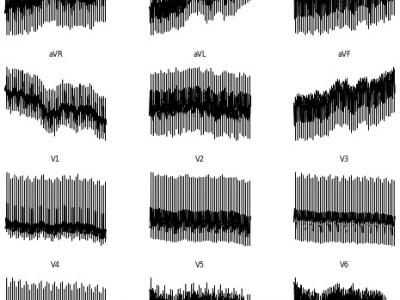
<p>Electrocardiogram (ECG) interpretation is critical for diagnosing a wide range of cardiovascular conditions. To streamline and accelerate the development of deep learning models in this domain, we present a novel, image-based version of the PTB Diagnostic ECG Database tailored for use with convolutional neural networks (CNNs), vision transformers (ViTs), and other image classification architectures. This enhanced dataset consists of 516 grayscale .png images, each representing a 12-lead ECG signal arranged as a 2D matrix (12 × T, where T is the number of time steps).
- Categories:
107 Views
The Travel Recommendation Dataset is a comprehensive dataset designed for building and evaluating conversational recommendation systems in the travel domain. It includes detailed information about users, destinations, and ratings, enabling researchers and developers to create personalized travel recommendation models. The dataset supports use cases such as personalizing travel recommendations, analyzing user behavior, and training machine learning models for recommendation tasks.
- Categories:
35 Views
This dataset compilation brings together four significant traffic network datasets from California's transportation monitoring systems: METR-LA, PEMS-BAY, PEMS04, and PEMS08. The METR-LA dataset is collected from the traffic monitoring system in the Los Angeles area and records detailed traffic speed data. The PEMS-BAY, PEMS04, and PEMS08 datasets originate from the California Department of Transportation (Caltrans) Performance Measurement System, with PEMS-BAY recording traffic speed data, while PEMS04 and PEMS08 record traffic flow data.
- Categories:
29 Views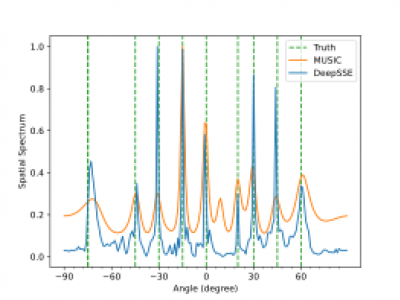
Dataset for multiple signal DOA estmation. This the original dataset used in our research. we consider a ULA with M = 16 antenna elements spaced at half-wavelength distance (l = λ/2). We consider narrowband, non-coherent signals with different intermediate frequencies (IF) transmitted from different sources. The signals are sampled at the intermediate frequency with a sampling frequency of 2.5MHz and 300 sample points. Then we simulate the array received signal according to signal model (1) at different SNRs of {-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5} dB.
- Categories:
125 Views
We evaluate the proposed FSDUF model on three publicly available social media benchmark datasets: Weibo {jin2017multimodal}, Twitter {boididou2015verifying}, and Pheme {zubiaga2017exploiting}.
- Categories:
16 Views
The NYUD V2 data set is comprised of video sequences from a variety of indoor scenes as recorded by both the RGB and Depth cameras from the Microsoft Kinect. It features: 1449 densely labeled pairs of aligned RGB and depth images 464 new scenes taken from 3 cities, 407,024 new unlabeled frames
- Categories:
18 Views
To generate the training and validation datasets, the fullwave electromagnetic solver FEKO is utilized. The phase of the reference antenna (Antenna 1) is fixed at 0°, while the phases of the other three antennas are varied in 30° steps within the range [0◦ , 360◦ ]. This results in 13×13×13 = 2197 distinct phase combinations. For each combination, the farfield radiation intensities are extracted on the XOY, YOZ, and XOZ planes, yielding a total of 2197 × 3 data samples. For testing, 343 new phase combinations are generated within the interval [15◦ , 195◦ ] using 30° steps (i.e., 7×7×7).
- Categories:
122 Views
To generate the training and validation datasets, the fullwave electromagnetic solver FEKO is utilized. The phase of the reference antenna (Antenna 1) is fixed at 0°, while the phases of the other three antennas are varied in 30° steps within the range [0◦ , 360◦ ]. This results in 13×13×13 = 2197 distinct phase combinations. For each combination, the farfield radiation intensities are extracted on the XOY, YOZ, and XOZ planes, yielding a total of 2197 × 3 data samples. For testing, 343 new phase combinations are generated within the interval [15◦ , 195◦ ] using 30° steps (i.e., 7×7×7).
- Categories:
90 Views