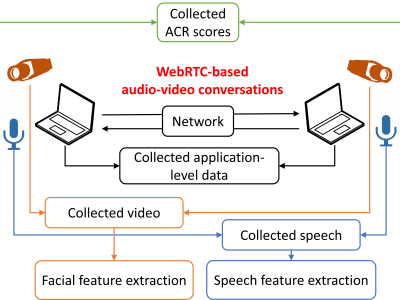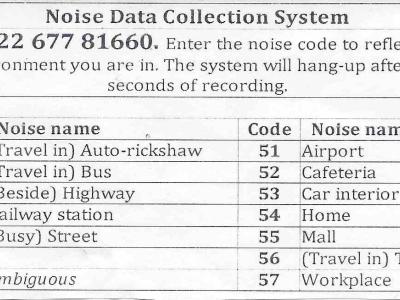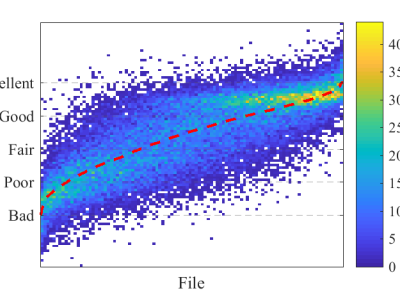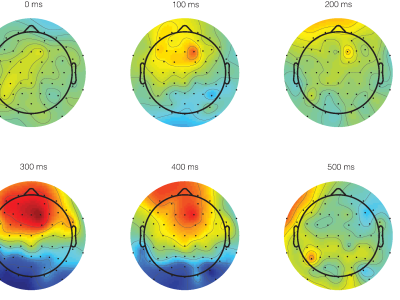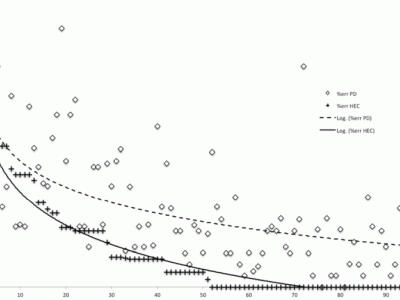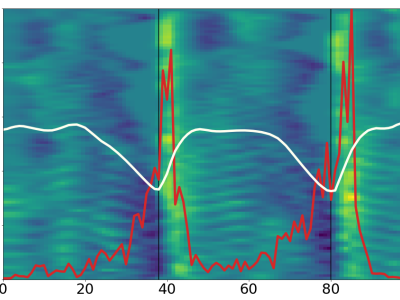
Objective, sensitive, and meaningful disease assessments are critical to support clinical trials and clinical care. Speech changes are one of the earliest and most evident manifestations of cerebellar ataxias. This data set contains features that can be used to train models to identify and quantify clinical signs of ataxic speech. Though raw audio or spectrograms cannot be released due to privacy concerns, this data set contains several OpenSMILE feature sets.
- Categories: