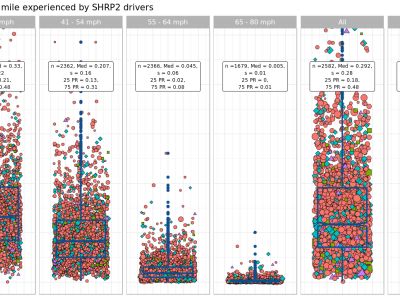
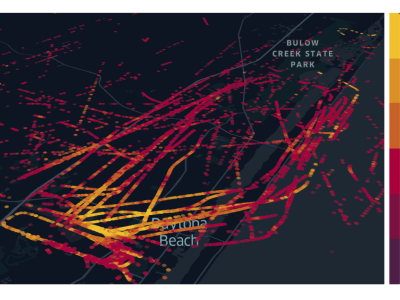
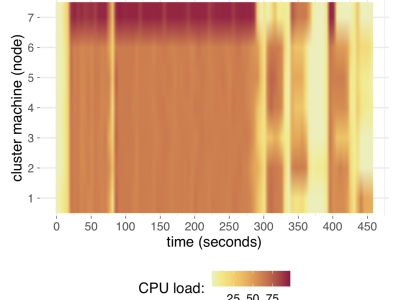
This is a dataset that contains the testing results presented in the manuscript "Exploring the Potential of Offline LLMs in Data Science: A Study on Code Generation for Data Analysis", and it aims to assess offline LLMs' capabilities in code generation for data analytics tasks. Best utilization of the dataset would occur after thorough understanding of the manuscript. A total of 250 testing results were generated for each of the two LLMs evaluated. They were merged, leading to the creation of this current dataset.
- Categories: