Dataset for An Ensemble Method for Keystroke Dynamics Authentication in Free-Text Using Word Boundaries
- Citation Author(s):
-
Nahuel González
 (Laboratorio de Sistemas de Información Avanzados)
(Laboratorio de Sistemas de Información Avanzados)
- Submitted by:
- Nahuel Gonzalez
- Last updated:
- DOI:
- 10.21227/jdzh-4m97
- Data Format:
- Links:
 506 views
506 views
- Categories:
- Keywords:
Abstract
Dataset used in the article "An Ensemble Method for Keystroke Dynamics Authentication in Free-Text Using Word Boundaries". For each user and free-text sample of the companion dataset LSIA, contains a CSV file with the list of words in the sample that survived the filters described in the article, together with the CSV files with training instances for each word. The source data comes from a dataset used in previous studies by the authors. The language of the free-text samples is Spanish.
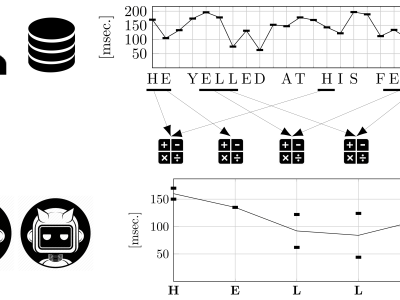
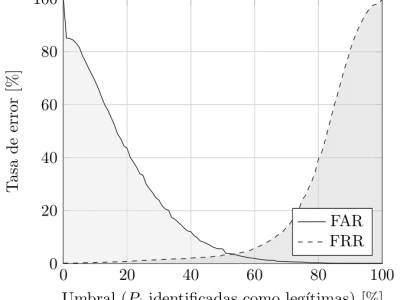
We introduce a novel ensemble method for keystroke dynamics authentication in free-text using word boundaries and individual classifiers. In contrast with other state-of-the-art methods which reach acceptable error rates with very little training, our method demands a large training set, in the order of 50.000 characters, but reaches a lower EER, around 2.5%, when evaluated in real-world conditions. Combining both approaches in a mixed scheme allows both objectives to be achieved; the first is used in the beginning when the training data is scarce, while the second excels after enough samples are available.
Instructions:
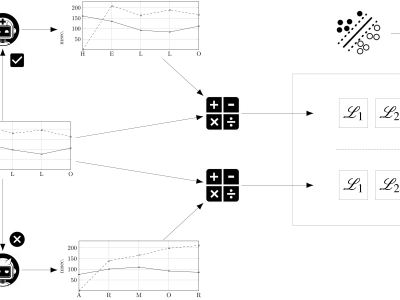
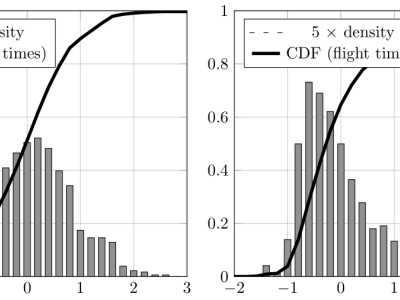
The source dataset LSIA contains many free-text typing samples for each user, consisting of a sequence of keystrokes where its hold times (down-up) and flight times (down-down) were recorded alongside other relevant information. All of the latter was ignored. Each user session was split at word boundaries, where any alphanumeric sequence is considered a word, for the purpose of training and evaluation. For each user and free-text sample, a CSV file with the list of words in the sample that survived the filters described in the article was generated, together with the CSV files with training instances for each word. There is a folder for each user, with a subfolder for each sample.
The CSV files with training instances for each word in each sample have been assembled from all the other samples of the same user, excepting the one under consideration; these were flagged as legitimate. The training instances consist of the hold times (down-up) and flight times (down-down) of the corresponding word. Only words having at least ten observations have been included. An equal number of training instances, flagged as impostors, were randomly collected from the samples of other users.
For the evaluation of EER, FAR, and FRR, one impostor sample is included besides each user and each legitimate sample. This was randomly chosen from the set of all samples of other users; the word models were created in this case using all the samples of the legitimate user and a similar process as described above for impostors.
The random forest implementation RandomForestClassifier of scikit-learn, version 0.24.2, was used for evaluation. Results are contained in CSV files, enumerating for each user, sample, and word, whether it was recognized as legitimate or impostor, and the accuracy of its individual classifier evaluated using five-fold cross validation.