Dataset for The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings
- Citation Author(s):
-
Nahuel González
 (Laboratorio de Sistemas de Información Avanzados)
(Laboratorio de Sistemas de Información Avanzados)
- Submitted by:
- Nahuel Gonzalez
- Last updated:
- DOI:
- 10.21227/7616-7964
- Data Format:
- Links:
 726 views
726 views
- Categories:
- Keywords:
Abstract
Dataset used in the article "The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings". Source data contains CSV files with dataset results summaries, false positives lists, the evaluated sentences, and their keystroke timings. Results data contains training and evaluation ARFF files for each user and sentence with the calculated Manhattan and euclidean distance, R metric, and the directionality index for each challenge instance. The source data comes from three free text keystroke dynamics datasets used in previous studies, by the authors (LSIA) and two other unrelated groups (KM, and PROSODY, subdivided in GAY, GUN, and REVIEW). Two different languages are represented, Spanish in LSIA and English in KM and PROSODY.
The original dataset KM was used to compare anomaly-detection algorithms for keystroke dynamics in the article "Comparing anomaly-detection algorithms forkeystroke dynamic" by Killourhy, K.S. and Maxion, R.A. The original dataset PROSODY was used to find cues of deceptive intent by analyzing variations in typing patterns in the article "Keystroke patterns as prosody in digital writings: A case study with deceptive reviews and essay" by Banerjee, R., Feng, S., Kang, J.S., and Choi, Y.
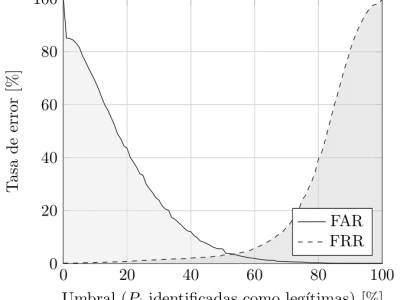
We proposed a method to find, using only flight times (keydown/keydown), whether a medium-sized candidate list of possible texts includes the one to which the timings belong. Nor the text length neither the candidate texts list were restricted, and previous samples of the timing parameters for the candidates were not required to train the model. The method was evaluated using three datasets collected by non-mutually-collaborating sets of authors in different environments. False acceptance and false rejection rates were found to remain below or very near to 1% when user data was available for training. The former increased between two- to three-fold when the models were trained with data from other users, while the latter jumped to around 15%. These error rates are competitive against current methods for text recovery based on keystroke timings, and show that the method can be used effectively even without user-specific samples for training, by recurring to general population data.
Instructions:
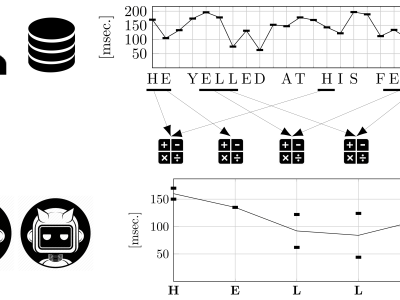
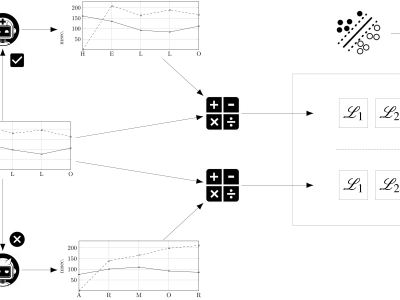
Each source dataset (LSIA, KM, and PROSODY) contains several typing sessions for each user, consisting of a sequence of keystrokes where its hold times (down-up) and flight times (down-down) were recorded alongside other relevant information. All of the latter was ignored. Each user session was split in sentences for the purpose of training and evaluation. Data files named DATASET-Sentences.txt, where DATASET is one of LSIA, KM, GAY, GUN, or REVIEW (the last three being subdivisions of PROSODY), contain the sentence IDs together with the user, text, hold times, and flight times.
Training ARFF files, named DATASET-USERxxx-TRAINING.arff, where xxx is the name of the user, contain the calculated Manhattan and euclidean distance, R metric, and the directionality index for each training instance, generated using finite context modelling as described in the article. Half of the instances, flagged as legitimate, correspond to correct texts and the other half, flagged as impostor, to wrong texts.
Evaluation ARFF files, named DATASET-USERxxx-SENTENCE-yyy.arff, where yyy is the sentence ID, contain the calculated Manhattan and euclidean distance, R metric, and the directionality index for each challenge instance. The first instance always corresponds to the correct text; the remaining one hundred are challenges corresponding to wrong texts.
The results for all sentences of each user are summarized in CSV files named DATASET-USERxxx.csv, which include sentence ID, sentence length, number of wrong text challenges, a flag determining whether the correct text was identified as such by the classifier, and the number of false positives. All false positives for the dataset are grouped in the files named DATASET-FalsePositives.txt, including columns user, sentence ID, correct text, and wrongly guessed text.
All files are grouped by training category and timing features considered. Those under the folder WithinUser employ user data as training, while those under the folder BetweenUser use general population statistics as training. Subfolder FT corresponds to training and evaluation using only flight times, and FTHT for both flight times and hold times.