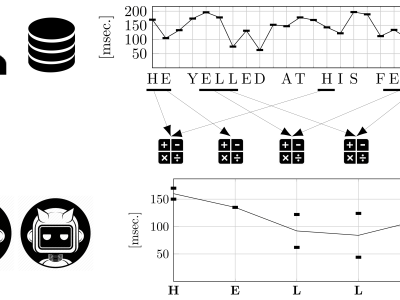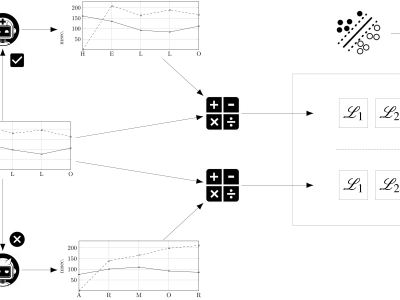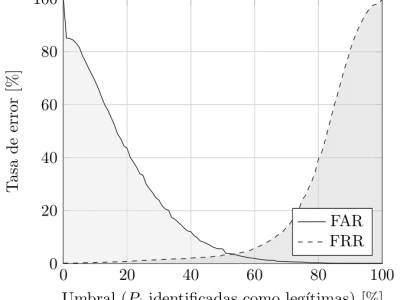
Dataset used in the article "An Ensemble Method for Keystroke Dynamics Authentication in Free-Text Using Word Boundaries". For each user and free-text sample of the companion dataset LSIA, contains a CSV file with the list of words in the sample that survived the filters described in the article, together with the CSV files with training instances for each word. The source data comes from a dataset used in previous studies by the authors. The language of the free-text samples is Spanish.
- Categories: