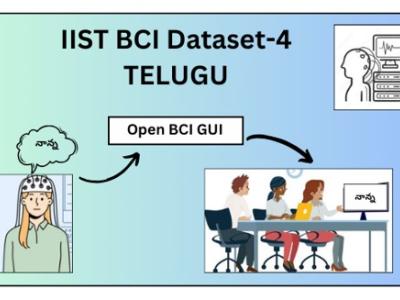
IIST BCI Dataset-4 for Selected 100 Telugu words
- Citation Author(s):
-
Chittaloori Likhitha
 (Chhattisgarh Swami Vivekanand Technical university, Bhilai,Chhattisgarh)
Shubham Tayade
(Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)
Parvathy S.S
(A. J College of Science and Technology, Thonnakkal)
Nancy Sunil
(A. J College of Science and Technology, Thonnakkal)
Shivani Sahoo (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)S Sumitra (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)B.S Manoj (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)
(Chhattisgarh Swami Vivekanand Technical university, Bhilai,Chhattisgarh)
Shubham Tayade
(Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)
Parvathy S.S
(A. J College of Science and Technology, Thonnakkal)
Nancy Sunil
(A. J College of Science and Technology, Thonnakkal)
Shivani Sahoo (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)S Sumitra (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram)B.S Manoj (Indian Institute of Space Science and Technology(IIST), Thiruvananthapuram) - Submitted by:
- Likhitha Chittaloori
- Last updated:
- DOI:
- https://doi.org/10.36227/techrxiv.171387874.40408574/v1
- Data Format:
 470 views
470 views
- Categories:
- Keywords:
Abstract
To address the challenges faced by patients with neurodegenerative disorders, Brain-Computer Interface (BCI) solutions are being developed. However, many current datasets lack inclusion of languages spoken by patients, such as Telugu, which is spoken by over 90 million people in India. To bridge this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of commonly used Telugu words. Using the Open-BCI Cyton device, EEG samples were captured from volunteers as they pronounced these words. This dataset is a valuable resource for researchers aiming to develop BCI solutions using Machine Learning (ML) classifiers and Deep Learning methods to translate EEG signals into Telugu words. In summary, our dataset facilitates the development of BCI solutions tailored to patients speaking Telugu, contributing to the advancement of assistive technologies for neurodegenerative disorder patients.
Instructions:
The dataset includes files produced by the OpenBCI Cyton Biosensing board.
RAW dataset is in format of text documents. EEG sample is stored as a file with text values separated by commas and arranged in rows and columns.
Column 1 - sample index is represented
Columns 2 to 9 - EEG recordings from the eight selected channels
Columns 10 to 22 and 24 contain unimportant data
Column 23 - representing time in a raw, unprocessed format.
Column 25 - displays the timestamp in YearMonth-Day Hour:Minute: Second format