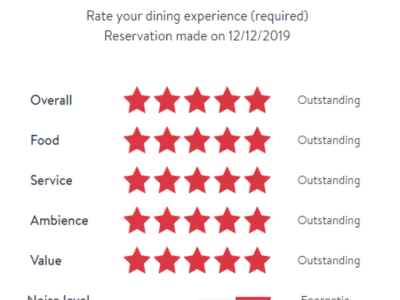
With the development of recommender systems (RS), several promising systems
have emerged, such as context-aware RS, multi-criteria RS, and group RS. However, the
education domain may not benefit from these developments due to missing information, such
as contexts and multiple criteria, in educational data sets. In this paper, we announce and
release an open data set for educational recommender systems. This data set includes not
only traditional rating entries, but also enriched information, e.g., contexts, user preferences