Datasets & Competitions

Dataset used in the article "An Ensemble Method for Keystroke Dynamics Authentication in Free-Text Using Word Boundaries". For each user and free-text sample of the companion dataset LSIA, contains a CSV file with the list of words in the sample that survived the filters described in the article, together with the CSV files with training instances for each word. The source data comes from a dataset used in previous studies by the authors. The language of the free-text samples is Spanish.
- Categories:
 502 Views
502 Views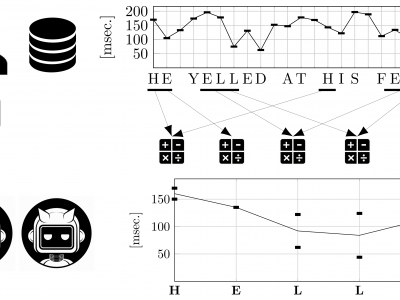
Dataset used in the article "The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings". CSV files with dataset results summaries, the evaluated sentences, detailed results, and scores. Results data contains training and evaluation ARFF files for each user, containing features of synthetic and legitimate samples as described in the article. The source data comes from three free text keystroke dynamics datasets used in previous studies, by the authors (LSIA) and two other unrelated groups (KM, and PROSODY, subdivided in GAY, GUN, and REVIEW).
- Categories:
517 Views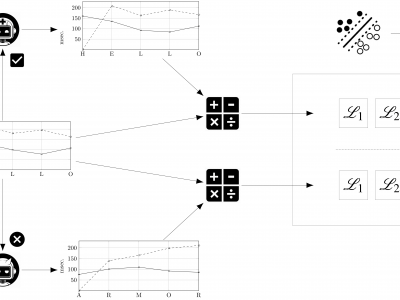
Dataset used in the article "The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings". Source data contains CSV files with dataset results summaries, false positives lists, the evaluated sentences, and their keystroke timings. Results data contains training and evaluation ARFF files for each user and sentence with the calculated Manhattan and euclidean distance, R metric, and the directionality index for each challenge instance.
- Categories:
661 Views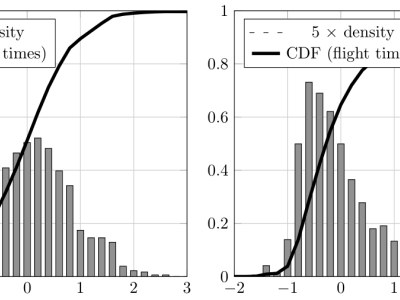
Dataset used in the article "On the shape of timing distributions in free text keystroke dynamics profiles". Contains CSV files with the timing features (hold times and flight times) of every keypress in three free text datasets used in previous studies, by the author (LSIA) and two other unrelated groups (KM from and PROSODY, subdivided in GAY, GUN, and REVIEW). The timing features are grouped by dataset, user, task, virtual key code, and feature. Two different languages are represented, Spanish in LSIA and English in KM and PROSODY.
- Categories:
407 Views