Artificial Intelligence

The Hindi Spam SMS Dataset comprises 3,894 messages, each labeled as either spam or ham. This dataset was meticulously curated with contributions from students who encountered these messages daily. The messages were collected from their experiences and those shared by friends and peers, ensuring a diverse and realistic representation of SMS communication in Hindi. It offers a representative sample of real-world Hindi text messages for analysis. The dataset primarily contains messages written in Hindi, reflecting its origin's linguistic and cultural context.
- Categories:
 110 Views
110 Views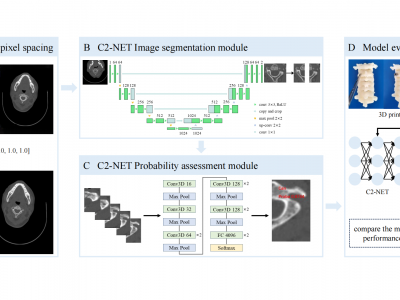
The lack of an objective and ready-to-use tool for preoperative planning in C2 pedicle screw placement surgery is notable. We developed C2-Net, a deep learning model for rapidly and accurately assessing C2 pedicle screw placement feasibility from CT images. C2-Net incorporates image segmentation and screw placement probability assessment modules.
- Categories:
76 Views
The dataset used in this study is a comprehensive, publicly available dataset designed for research purposes, encompassing various features related to the public sector. It includes data on all genders (male and female) from diverse regions, age groups, and educational levels. The dataset was sourced from CAPMAS reports (2018-2023), which provide quarterly updates on the labor force, including details on unemployment assessments categorized by geographical distribution.
- Categories:
35 Views
Dig21000 is a comprehensive dataset consisting of 21,000 images of digit-based rotary meters photographed in uncontrolled environments.
It integrates images from open datasets on the Roboflow platform and those independently collected.
After undergoing cleaning, the images are randomly divided into training and testing sets at a ratio of 6:1.
It contains 10 digit categories. The images are affected by multiple factors and can be used for research on digital dial recognition. It is publicly available and citation is required when using it.
- Categories:
92 Views
To further evaluate the practical performance of HPDM, we apply it to detect defects in actual industrial circuit boards. Various defects, such as board, lifting, and ffipping defects, occur on the circuit board because of external forces imposed during the placement and soldering processes .A real industrial circuit board defect detection dataset is collected and presented. This dataset includes five different categories of components with various real multiscale defects.
- Categories:
170 Views
To ensure reproducible experiments and prevent overburdening the server, we construct an SQL-based database dubbed RiPAMI (Reviews in Pattern Analysis and Machine Intelligence, pronounced as \textipa{/ri:p\ae mi/}). This database stores information related to the paper such as title, abstract, date of publication, venue, citation counts, and reference details, etc. From initial keyword selection to the final SQL-based RiPAMI snapshot, three key steps are implemented to ensure the data in RiPAMI is clean, accurate, and reliable.
- Categories:
18 Views
Large vision-language models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation tasks. However, these models occasionally generate hallucinatory texts, resulting in descriptions that seem reasonable but do not correspond to the image. This phenomenon can lead to wrong driving decisions of the autonomous driving system.
- Categories:
18 Views
A dataset of simulated resistive drift series for an illustrative stochastic memristor.
Dataset Description
The memristor has an equilibrium resistance of approximately 500kΩ.
5000 series are generated with starting resistances sampled uniformly from the range [100Ω, 750kΩ].
Each series consists of 1001 datapoints, with the first (zeroth) point corresponding to the initial resistance, and subsequent points sampled at subsequent timesteps.
Dataset Creation
- Categories:
34 Views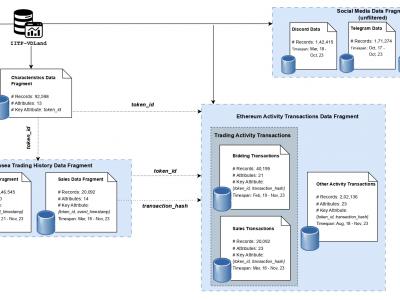
IITP-VDLand is a comprehensive dataset of Decentraland parcels sourced from diverse platforms such as Decentraland, OpenSea, Etherscan, Google BigQuery, and various Social Media Platforms. Unlike existing datasets which have limited attributes and records, IITP-VDLand offers a rich array of attributes, encompassing parcel characteristics, trading history, past activities, transactions, and social media interactions. Alongside, we introduce a key attribute in the dataset, namely Rarity score, which measures the uniqueness of each parcel within the virtual world.
- Categories:
245 Views
A multimodal dataset is presented for the cognitive fatigue assessment of physiological minimally invasive sensory data of Electrocardiography (ECG) and Electrodermal Activity (EDA) and self-reporting scores of cognitive fatigue during HRI. Data were collected from 16 non-STEM participants, up to three visits each, during which the subjects interacted with a robot to prepare a meal and get ready for work. For some of the visits, a well-established cognitive test was used to induce cognitive fatigue.
- Categories:
143 Views