Artificial Intelligence

This large dataset includes six small datasets, including two types, one contains the original node relationship information and node feature information, please use it through the common network construction methods; the other is the dataset which has been processed, including the direct edge information and node's association information, which can be used to construct the network directly through the network construction methods.
- Categories:
 256 Views
256 Views
The LuFI-RiverSnap dataset includes close-range river scene images obtained from various devices, such as UAVs, surveillance cameras, smartphones, and handheld cameras, with sizes up to 4624 × 3468 pixels. Several social media images, which are typically volunteered geographic information (VGI), have also been incorporated into the dataset to create more diverse river landscapes from various locations and sources.
Please see the following links:
- Categories:
595 Views
We have developed three datasets, referred to as ER-C, Mito-C and Nucleus-C, respectively, for benchmarking robustness of DNN models against corruptions and adversarial attacks in semantic segmentation of fluorescence microscopy images. Degraded images in these three datasets are synthesized from raw images along with their manually annotated segmentation labels in the ER, Mito, and Nucleus datasets [1,2], respectively.
- Categories:
112 Views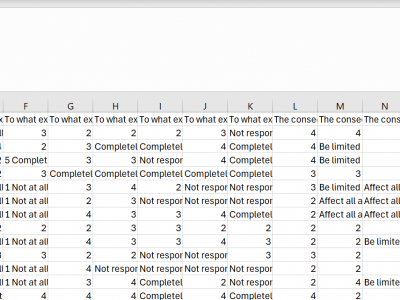
This dataset focuses on the redevelopment and psychometric evaluation of the Adversity Response Profile for Indian Higher Education Institution (ARP-IHEI) students, emphasizing its importance in understanding how individuals respond to adversity. The data were gathered from a sample of 122 second year students at school of computing, MIT Art, Design and Technology University students. Read_me file contains questionnaire.
- Categories:
193 Views
The large and diverse access to data sources in healthcare has boosted the application of novel computer techniques that can extract meaningful information to improve patients' prognoses and other important medical uses. However, current systems require the professional to manually type the information, which increases the risk of transcription errors and cross-contamination. We propose an automated system that allows healthcare professionals to dictate clinical information that can be transcribed and analyzed.
- Categories:
95 Views
This dataset comprises over 38,000 seed inputs generated from a range of Large Language Models (LLMs), including ChatGPT-3.5, ChatGPT-4, Claude-Opus, Claude-Instant, and Gemini Pro 1.0, specifically designed for the application in fuzzing Python functions. These seeds were produced as part of a study evaluating the utility of LLMs in automating the creation of effective fuzzing inputs, a method crucial for uncovering software defects in the Python programming environment where traditional methods show limitations.
- Categories:
175 Views
This dataset includes environmental perception, vehicle motion status, and battery consumption during vehicle operation. The dataset is collected by human operators during the safe and smooth operation of vehicles. By dividing the hazardous areas in the current environment of the vehicle and processing them, a radar map of the hazardous areas is generated; The vehicle motion status section contains the position information (x, y, z) and kinematic information (v, w, a, alpha, beta, gamma) of the vehicle.
- Categories:
690 Views
This study used boots, aircraft, cells, pliers, and guitars from 2D shapes included in the literature as data sets to test modeling success. These 2D shapes, which are mostly not publicly available data sets, form the target curves of IP. In this study, hand drawings with a curved structure were used in modeling, where the success of fitting precision could be better determined.
- Categories:
67 Views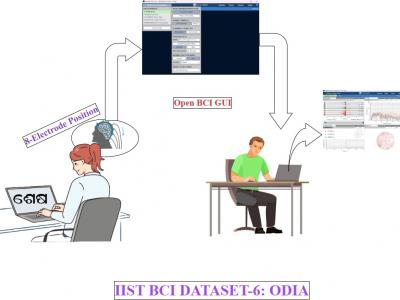
Brain-Computer Interface (BCI) is a technology that enables direct communication between the brain and external devices, typically by interpreting neural signals. BCI-based solutions for neurodegenerative disorders need datasets with patients’ native languages. However, research in BCI lacks insufficient language-specific datasets, as seen in Odia, spoken by 35-40 million individuals in India. To address this gap, we developed an Electroencephalograph (EEG) based BCI dataset featuring EEG signal samples of commonly spoken Odia words.
- Categories:
302 Views
The dataset consists of around 335K real images equally distributed among 7 classes. The classes represent different levels of rain intensity, namely "Clear", "Slanting Heavy Rain", "Vertical Heavy Rain", "Slanting Medium Rain", "Vertical Medium Rain", "Slanting Low Rain", and "Vertical Low Rain". The dataset has been acquired during laboratory experiments and simulates a low-altitude flight. The system consists of a visual odometry system comprising a processing unit and a depth camera, namely an Intel Real Sense D435i.
- Categories:
199 Views