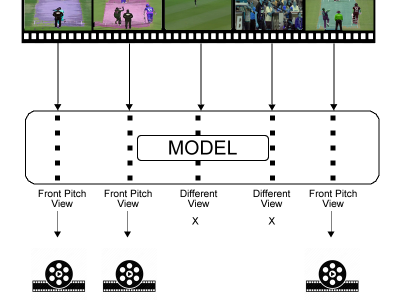
The use of technology in cricket has seen a significant increase in recent years, leading to overlapping computer vision-based research efforts. This study aims to extract front pitch view shots in cricket broadcasts by utilizing deep learning. The front pitch view (FPV) shots include ball delivery by the bowler and the stroke played by the batter. FPV shots are valuable for highlight generation, automatic commentary generation and bowling and batting techniques analysis. We classify each broadcast video frame as FPV and non-FPV using deep-learning models.
- Categories:




