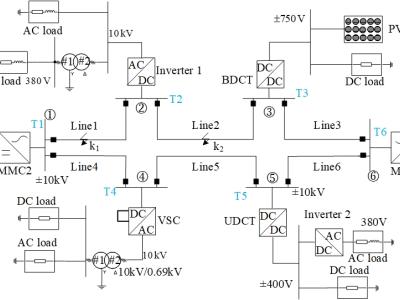
To verify the proposed protection scheme, the simulation model of a six-terminal ring flexible DC distribution system is built in PSCAD/EMTDC , where the rated voltage of the DC line is ±10 kV . The fault inception is set at 0.6 s, the sampling frequency is 10 kHz and the protection data window length is 1 ms. The data set reflects the current and voltage values of each line after standardization
- Categories:

