Artificial Intelligence
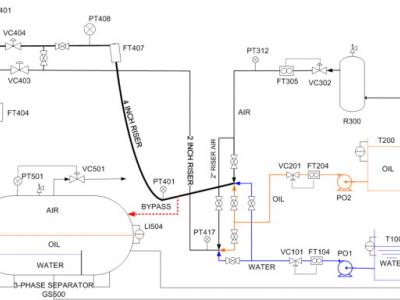
Dateset of the Three-Phase Flow Facility. The Three-phase Flow Facility at Cranfield University is designed to provide a controlled and measured flow rate of water, oil and air to a pressurized system. Fig. 1 shows a simplified sketch of the facility. The test area consists of pipelines with different bore sizes and geometries, and a gas and liquid two-phase separator (0.5 m diameter and 1.2 m high) at the top of a 10.5 m high platform. It can be supplied with single phase of air, water and oil, or a mixture of those fluids, at required rates.
- Categories:
 82 Views
82 ViewsWe propose MM-Vet v2, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development.
- Categories:
83 Views
Dataset 1 include 100 rebar-reinforced rectangular UHPC beams data.
- Categories:
5 Views
The analysis suggests various innovative ideas to improve English instruction, with an emphasis on current technologies and an inclusive approach. These include using AI as a peer tutor, exploring virtual reality to create immersive learning environments, analyzing data to create customized learning materials, integrating local cultural values into instructional materials, implementing a technology-based inclusive learning model, implementing a policy for digital advancement in education, and making the most of contemporary learning resources.
- Categories:
75 Views
Our paper presents a novel approach to enhance vulnerability descriptions using code-based methods for predicting missing phrase-based concepts. We leverage Large Language Models (LLMs) integrated with 1-hop relationship analysis to address hallucination issues. The code processes Textual Vulnerability Descriptions (TVDs) and extracts relevant security-related concepts such as vulnerability type, root cause, and impact. Our methodology involves generating predictions, verifying these with external knowledge sources, and filtering inaccurate results.
- Categories:
6 Views
This dataset provides 98208 self-play history data of a MahJong agent using MahJong Competition Rules. This dataset provides 98208 self-play history data of a MahJong agent using MahJong Competition Rules. This dataset provides 98208 self-play history data of a MahJong agent using MahJong Competition Rules. This dataset provides 98208 self-play history data of a MahJong agent using MahJong Competition Rules. This dataset provides 98208 self-play history data of a MahJong agent using MahJong Competition Rules. This dataset provides 98208 self-play history data of a MahJong agent using MahJon
- Categories:
26 Views
All the healthcare facilites in this dataset were collected from the MOH 2018 list of Uganda healthcare facilites (https://library.health.go.ug/sites/default/files/resources/National%20Health%20Facility%20MasterLlist%202017.pdf) Additional features were scraped using the Google Maps API and additionally from some of the websites of the healthcare facilities themselves.
- Categories:
29 Views
This paper describes a dataset of droplet images captured using the sessile drop technique, intended for applications in wettability analysis, surface characterization, and machine learning model training. The dataset comprises both original and synthetically augmented images to enhance its diversity and robustness for training machine learning models. The original, non-augmented portion of the dataset consists of 420 images of sessile droplets. To increase the dataset size and variability, an augmentation process was applied, generating 1008 additional images.
- Categories:
90 Views
The datasets used for TKDE manuscript. These datasets are widely recognized and validated within the summarization research community, and using these well-established datasets ensures that our results are comparable with the vast majority of related work.In each dataset, we use 80% as the training set, while the remaining 20% as the test data. The range of datasets used for collecting knowledge is also consistent with the above. For the large dataset, we only use a part of it because collecting knowledge is time-consuming.
- Categories:
12 Views
Imaging, Pathology, and Psychological Research on Neuroimmune Gastrointestinal Diseases
- Categories:
76 Views