Artificial Intelligence

This dataset contains simulated records for 3,000 students, generated for the purpose of evaluating fairness in predicted grading models. The dataset includes decile rankings based on historical performance, predicted grades, and demographic attributes such as socioeconomic status, school type, gender, and ethnicity. The data was created using controlled randomization techniques and includes noise to reflect real-world prediction uncertainty. While entirely synthetic, the dataset is designed to mimic key structural patterns relevant to algorithmic fairness and educational inequality.
- Categories:
 9 Views
9 Views
This dataset contains simulated records for 3,000 students, generated for the purpose of evaluating fairness in predicted grading models. The dataset includes decile rankings based on historical performance, predicted grades, and demographic attributes such as socioeconomic status, school type, gender, and ethnicity. The data was created using controlled randomization techniques and includes noise to reflect real-world prediction uncertainty. While entirely synthetic, the dataset is designed to mimic key structural patterns relevant to algorithmic fairness and educational inequality.
- Categories:
13 Views
This dataset consists of images with two types of artificially added noise, intended for evaluating the robustness of machine learning models against noise perturbations. The first type of noise introduces randomly generated pixel values ranging from 0 to 255 at random positions in the image. The second type of noise adds binary noise by setting pixels at random locations to either 0 or 255. The dataset includes images with varying amounts of noisy pixels, allowing for detailed analysis under different noise intensities.
- Categories:
26 Views
This paper explores public perceptions surrounding the use of Artificial Intelligence (AI) in cultural and media production across the Arab region. Based on a comprehensive questionnaire distributed among 2000 participants, the study investigates attitudes toward AI-driven content, ethical concerns, cultural identity threats, educational impacts, and legal responsibilities.
- Categories:
91 Views

Digital microfluidics are a unique technique for operation of nano-to-micro liter droplets based on electrowetting on dielectric. It has great application potential in the field on clinic diagnosis, life science and environment monitoring. Due to the fast droplet moving speed and high degree of freedom for droplet manipulation, it is urgent to develop automated and intelligent approaches for droplet monitoring and control.
- Categories:
42 Views
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets face limitations: they rely on human annotators who assess code primarily through semantic understanding rather than functional verification, leading to potential inaccuracies and scalability issues. Additionally, current evaluation metrics often overlook the multi-choice nature of code search. This paper introduces CoSQA+, pairing high-quality queries from CoSQA with multiple suitable codes.
- Categories:
4 Views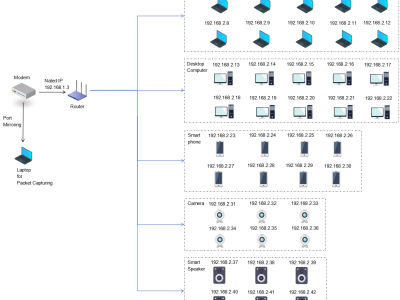
three-level network topology experimental environment was constructed based on a typical home network. An optical network terminal (Bell XE-140W-TD) was used as the starting point for Internet access, and a Gigabit wired connection was established with the core router (Huawei TC30) via a shielded Cat 6 cable. This router is a Huawei beta version that can obtain specific device information and corresponding traffic after NAT. The experimental evaluation of traffic attribution association in subsequent chapters will use this as ground truth label data for comparison.
- Categories:
39 Views
This dataset provides packet traces captured in a realistic 5G Vehicle-to-Everything (5G-V2X) environment, encompassing both legitimate vehicular communications and Distributed Denial of Service (DDoS) attacks. By deploying four user equipments (UEs) under multiple attacker configurations, the collected captures reflect various DDoS types (TCP SYN, UDP, and mixed) and reveal their impact on 5G-V2X networks. The dataset is further enriched with Argus files and CSV feature tables, facilitating data-driven approaches such as Machine Learning (ML)-based detection agents.
- Categories:
367 Views
This is the dataset for paper VI-BEVSEG training and testing. For more details about the dataset structure, please refer to Nuscense or V2X-Sim. We only use the number 1 vehicle in the V2X-Sim dataset. Replace the folder in this dataset, and only keep the vehicle 1 six onboard cameras information, infrastructure camera information and their semantic camera information in 'sweeps' and 'samples' folder. Then replace the 'v1.0-trainval' folder with ours and put the h5 maps under V2X-Sim folder.
- Categories:
14 Views