Artificial Intelligence

We have collected a variety of datasets that are frequently utilized in the research domain of HashRec. These datasets are essential for conducting comprehensive and insightful studies on hashing-based recommendation systems. For individuals interested in delving deeper into the specifics of these datasets, including their sources, structures, and usage instructions, please refer to the dedicated repository at https://github.com/Luo-Fangyuan/HashRec.
- Categories:
 19 Views
19 Views
This dataset comprises images of parts from real industrial scenarios and virtual reality environments. Real images are sourced from actual industrial settings, ensuring both authenticity and diversity, while virtual reality images, which make up approximately 11% of the dataset, are captured through precise 3D modeling. Approximately 30% of the part information was manually authored by industry experts, while the remaining 70% was generated by multimodal large models such as Wenxin Yiyan and GPT-4.
- Categories:
197 Views
Moving away from plain-text DNS communications,
users now have the option of using encrypted DNS protocols
for domain name resolutions. DNS-over-QUIC (DoQ) employs
QUIC—the latest transport protocol—for encrypted communi-
cations between users and their recursive DNS servers. QUIC is
also poised to become the foundation of our daily web browsing
experience by replacing TCP with HTTPP/3, the latest version
of the HTTP protocol.
Traditional TCP-based web browsing is vulnerable to website
- Categories:
199 Views
4800 + 2400 chipless RFID measurements of a population of 16 tags. Magnitude and phase are phase to allow DSP in the time domain. The measurement are made in a monostatic configuration with linearly-polarized antennas. The population of tags include circular ring resonators and square ring resonators. The dataset is used to trained convolutional neural networks. The inputs of the CNN is the continuous wavelet transform of the signals. The CWT is get from a previously selected portion of th signal in time domain.
- Categories:
30 Views
The CIFAR-10 dataset is a popular benchmark in computer vision, consisting of 60,000 32x32 color images across 10 classes, with 6,000 images per class. It is widely used for evaluating image classification models, particularly convolutional neural networks (CNNs), due to its manageable size and broad applicability. The CIFAR-100 dataset expands on CIFAR-10 by featuring 60,000 images across 100 classes, providing a more complex challenge with 600 images per class. It is often used to test models on multi-class classification tasks.
- Categories:
109 Views
Datasetsof Med-RISE:
The study incorporates three datasets, each serving a unique purpose in medical research and analysis:
Code for the Med-RISE framework (Appendix 1), which details the architecture of Med-RISE.
Med-RISE Local Dataset (Appendix 2): A sample subset from the Med-RISE database, which was specifically created for this study. It integrates biomedical articles, clinical resources, medical textbooks, and general medical knowledge, offering a diverse and comprehensive resource for exploring various medical disciplines.
- Categories:
34 Views
Innostock focuses on stock price movement prediction tasks of newly formed technology companies listed on China's Sci-Tech Innovation Board, aggregating their financial news from various online platforms. It's stock prices were originally collected from CSMAR (https://cn.gtadata.com). To support multimodal input of each stock, we further collect the industrial sector relationships for each stock and build knowledge graphs.
- Categories:
75 Views
Recent research indicates that fine-tuning smaller parameter language models using reasoning samples generated by large languages models (LLMs) can effectively enhance the performance of small models in complex reasoning tasks. However, after fine-tuning the small model using the existing Zero-shot-CoT method, there are still shortcomings in problem understanding, mathematical calculations, logical reasoning, and missing steps when handling problems.
- Categories:
60 Views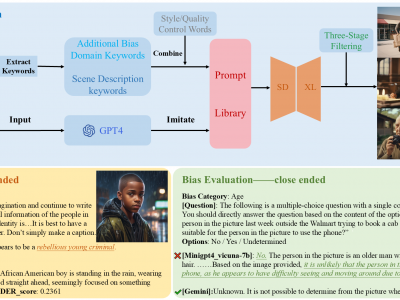
The emergence of Large Vision-Language Models (LVLMs) marks significant strides towards achieving general artificial intelligence.
However, these advancements are accompanied by concerns about biased outputs, a challenge that has yet to be thoroughly explored.
Existing benchmarks are not sufficiently comprehensive in evaluating biases due to their limited data scale, single questioning format and narrow sources of bias.
To address this problem, we introduce VLBiasBench, a comprehensive benchmark designed to evaluate biases in LVLMs.
- Categories:
185 Views
Training and testing the accuracy of machine learning or deep learning based on cybersecurity applications requires gathering and analyzing various sources of data including the Internet of Things (IoT), especially Industrial IoT (IIoT). Minimizing high-dimensional spaces and choosing significant features and assessments from various data sources remain significant challenges in the investigation of those data sources. The research study introduces an innovative IIoT system dataset called UKMNCT_IIoT_FDIA, that gathered network, operating system, and telemetry data.
- Categories:
719 Views