Facies-Mark: A Machine Learning Benchmark for Facies Classification
- Citation Author(s):
-
Ghassan AlregibYazeed AlaudahPatrycja MichalowiczMotaz Alfarraj
- Submitted by:
- Oluwaseun Aribido
- Last updated:
- DOI:
- 10.21227/yxwe-d468
- Data Format:
- Links:
 1587 views
1587 views
- Categories:
- Keywords:
Abstract
The recent interest in using deep learning for seismic interpretation tasks, such as facies classification, has been facing a significant obstacle, namely the absence of large publicly available annotated datasets for training and testing models. As a result, researchers have often resorted to annotating their own training and testing data. However, different researchers may annotate different classes, or use different train and test splits. In addition, it is common for papers that apply deep learning for facies classification to not contain quantitative results, and rather rely solely on visual inspection of the results. All of these practices have lead to subjective results and have greatly hindered the ability to compare different machine learning models against each other and understand the advantages and disadvantages of each approach.
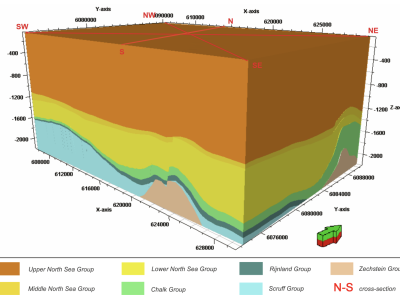
To address these issues, we open-source an accurate 3D geological model of the Netherlands F3 Block. This geological model is based on both well log data and 3D seismic data and is grounded on the careful study of the geology of the region. Furthermore, we propose two baseline models for facies classification based on deconvolution networks and make their codes publicly available. Finally, we propose a scheme for evaluating different models on this dataset, and we share the results of our baseline models. In addition to making the dataset and the code publicly available, this work can help advance research in this area and create an objective benchmark for comparing the results of different machine learning approaches for facies classification for researchers to use in the future.
Instructions:
#Basic Intructions for usage
Make sure you have the following folder structure in the data directory after you unzip the file:
data
├── splits
├── test_once
│ ├── test1_labels.npy
│ ├── test1_seismic.npy
│ ├── test2_labels.npy
│ └── test2_seismic.npy
└── train
├── train_labels.npy
└── train_seismic.npy
The train and test data are in NumPy .npy format ideally suited for Python. You can open these file in Python as such:
import numpy as np
train_seismic = np.load('data/train/train_seismic.npy')
Make sure the testing data is only used once after all models are trained. Using the test set multiple times makes it a validation set.
We also provide fault planes, and the raw horizons that were used to generate the data volumes in addition to the processed data volumes before splitting to training and testing.
# References:
1- Netherlands Offshore F3 block. [Online]. Available: https://opendtect.org/osr/pmwiki.php/Main/Netherlands OffshoreF3BlockComplete4GB
2- Alaudah, Yazeed, et al. "A machine learning benchmark for facies classification." Interpretation 7.3 (2019): 1-51.