First Name
Oluwaseun
Last Name
Aribido
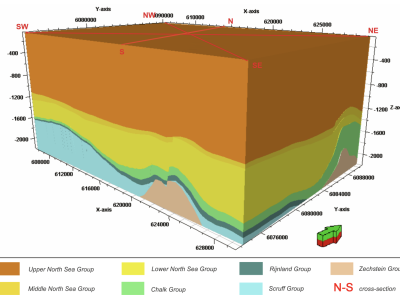
The recent interest in using deep learning for seismic interpretation tasks, such as facies classification, has been facing a significant obstacle, namely the absence of large publicly available annotated datasets for training and testing models. As a result, researchers have often resorted to annotating their own training and testing data. However, different researchers may annotate different classes, or use different train and test splits.