IIST BCI Dataset-9: EEG Dataset For Malayalam Vocal and Subvocal Commands with Dialect Variation For Wheelchair Control

- Citation Author(s):
-
Seetha D K
 (Nehru Arts and Science College, Kanhangad, Kasaragod)
Sibi M S
(Nehru Arts and Science College, Kanhangad, Kasaragod)
Shivani Sahoo
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
K. B. Sheetal
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Navya Anil
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Neethu Sajeev
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Anjana K
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Sruthi N T
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
S. Sumitra
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
B. S. Manoj
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
(Nehru Arts and Science College, Kanhangad, Kasaragod)
Sibi M S
(Nehru Arts and Science College, Kanhangad, Kasaragod)
Shivani Sahoo
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
K. B. Sheetal
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Navya Anil
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Neethu Sajeev
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Anjana K
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
Sruthi N T
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
S. Sumitra
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
B. S. Manoj
(Indian Institute of Space Science and Technology (IIST), Trivandrum)
- Submitted by:
- Seetha D K
- Last updated:
- DOI:
- 10.21227/yd6y-z680
- Data Format:
- Research Article Link:
 19 views
19 views
- Categories:
- Keywords:
Abstract
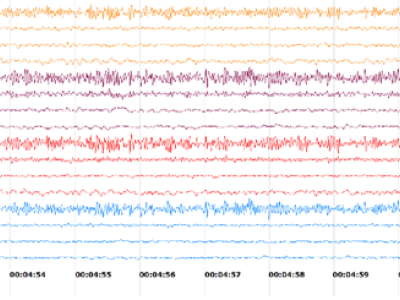
We developed IIST BCI Dataset-9, a novel EEG-based Brain-Computer Interface (BCI)
dataset to improve wheelchair control systems using Malayalam dialect variations. BCI
systems help people with motor disabilities by allowing them to control devices using brain
signals. The limited number of BCI datasets in Indian languages makes it harder for native
speakers to use these systems. To address this, we created a dataset with 15 Malayalam
words related to basic wheelchair commands like Forward, Backward, Go, Stop, Reverse,
Right, and Left. The volunteer pronounced these words vocally and subvocally, each
repeated 10 times. Non-invasive Electroencephalography (EEG) sensors were employed to
capture the brain activity associated with these tasks. Data was collected from volunteers
across 10 districts of Kerala to include different language variations. This dataset can help
improve machine learning and BCI systems by making them more accurate and
user-friendly. It also supports the development of assistive technologies for
Malayalam-speaking individuals with neurological conditions.
Instructions:
- The IIST_BCI_DATASET-9 dataset is organized into a main folder with two subfolders:
PROCESSED_DATA and RAW_DATA, along with a Python script file, processing_code.py. - Both subfolders (PROCESSED_DATA and RAW_DATA) contain SUBVOCAL and VOCAL
folders, each with 7 command folders — Forward, Backward, Go, Stop, Reverse, Right, and
Left — and 10 trial folders per command, each containing 15 dialect variations. - The RAW_DATA folder contains unprocessed EEG data in .txt format from the OpenBCI
Cyton Biosensing board. - Each raw data file contains sample indices and EEG data from eight channels (EXG
channels 0 to 7). Additional irrelevant data in columns 10 to 22 and 24. Column 23 holds the
Unix timestamp, and column 25 contains a human-readable timestamp. - The PROCESSED_DATA folder contains cleaned EEG data in .csv format.
- The processing_code.py script removes irrelevant columns (such as timestamps), keeps
only the EEG signals from channels 0 to 7, and saves the cleaned data as .csv files. The
script processes one file at a time to ensure efficient data preparation. - The dataset offers both raw and processed EEG data in an organized structure, with the
script facilitating the preprocessing of raw files into usable formats for analysis. - This structured format allows for efficient processing and analysis of EEG data for various
research and clinical applications.
For more details, go through the Data Descriptor Paper.