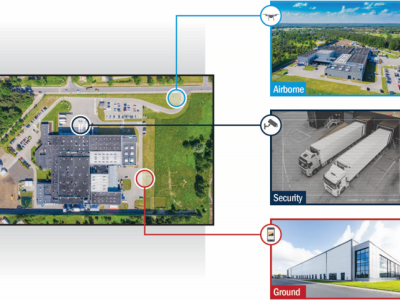
The ULTRRA challenge evaluates current and novel state of the art view synthesis methods for posed and unposed cameras. Challenge datasets emphasize real-world considerations, such as image sparsity, variety of camera models, and unconstrained acquisition in real-world environments.
- Categories:


