Artificial Intelligence

The data set includes three sub-data sets, namely the DAGM2007 data set, the ground crack data set, and the Yibao bottle cap defect data set, which are divided into a training set and a test set, in which the positive and negative samples are unbalanced.
- Categories:
 2216 Views
2216 Views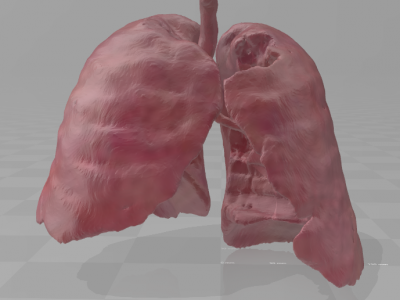
Nextmed project is a software platform for the segmentation and visualization of medical images. It consist on a series of different automatic segmentation algorithms for different anatomical structures and a platform for the visualization of the results as 3D models.
This dataset contains the .obj and .nrrd files that correspond to the results of applying our automatic lung segmentation algorithm to the LIDC-IDRI dataset.
This dataset relates to 718 of the 1012 LIDC-IDRI scans.
- Categories:
779 Views
Computer vision can be used for environment-adaptive control of robotic exoskeletons and prostheses. However, small-scale and private training datasets have impeded the development of image classification algorithms (e.g., convolutional neural networks) to recognize the walking environment. To address these limitations, we developed ExoNet, a large-scale dataset of wearable camera images (i.e., egocentric perception) of real-world walking environments.
- Categories:
5889 Views
The dataset is used to detect essential protein in uncertain PPI network.
- Categories:
97 Views
The PPI datasets were collected from four different sources: DIP, MIPS, Gavin, and Krogan. All self-interactions and repeated interactions were filtered. The essential proteins were collected from the following four different databases: MIPS,SGD,DEGand SGDP (http://www.sequence.stanford.edu/group/). Gene expression data were downloaded from the Gene Expression Omnibus (GEO) database (http://www.ncbi.nlm.nih.gov/geo/) with accession number GSE3431.
- Categories:
357 Views
A Chinese dataset for table-to-text generation named WIKIBIOCN which inculeds 33,244 biography sentences with related tables from Chinese Wikipedia (July 2018).
The dataset is divided into training set (30,000), verification set (1000) and test set (2,244).
- Categories:
170 Views
We conduct experiments with the datasets of SemEval 2014 task4 to evaluate our model, the SemEval 2014 datasets consist of reviews in two categories: Restaurant and Laptop, and the reviews contains three labels of sentiment polarity: {positive, negative, neutral}
- Categories:
249 Views
We crawled large amounts of biomedical articles from PubMed for the keyphrase extraction system evaluation.
The articles, that consist of title, abstract and keyphrases provided by the authors, are used for the experiments.
In our paper, cancer-related biomedical articles are selected.
- Categories:
600 Views
Since there is no image-based personality dataset, we used the ChaLearn dataset for creating a new dataset that met the characteristics we required for this work, i.e., selfie images where only one person appears and his face is visible, labeled with the person's apparent personality in the photo.
- Categories:
3559 Views