
This dataset supports the research on the "Bed Stories" information retrieval system, designed to help children retrieve relevant story content based on semantic query expansion using WordNet ontology.
- Categories:

The heat production rate data of lunar major basins were obtained from the Chang 'e-2 gamma-ray spectrometer data (http://moon.bao.ac.cn). A detailed description of the processing procedure for these data products is provided by Zhao et al. [2023]. The map bin size is 1.5° by 1.5°. The unit of heat production rate in these data is μW/m³.

The QRF dataset is designed to support research in quantum-native photorealistic scene rendering. It consists of high-fidelity 3D indoor and outdoor environments captured from multiple calibrated viewpoints, with detailed annotations of geometry, material properties, and lighting conditions. Each scene is processed into quantum-compatible representations for training and evaluating Quantum Radiance Fields (QRF), which leverage quantum circuits, activation functions, and quantum volume rendering.

This dataset contains field test data of multi-USV collaborative area search and dynamic target trapping operations performed on a lake.
In order to accelerate the CU partitioning in VVC-SCC, we have established a specialized dataset for screen content. Firstly, we collect a wide variety of screen content videos and images in YUV format. Secondly, we encode these sequences under four different Quantization Parameters (QPs) to obtain comprehensive information about CU partitioning in VVC-SCC. This includes the length, width, position, mode labels, and RDcost values corresponding to each mode. This dataset will provide valuable data support for optimizing the CU partitioning process in screen content coding.
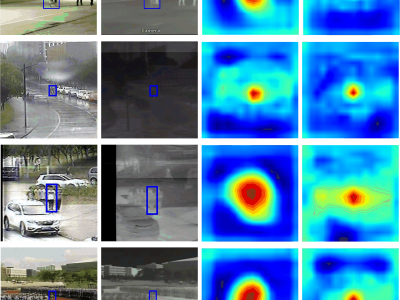
We are pleased to submit our manuscript entitled "Hetero-modal Template Guide Search Region for RGBT Tracking" for consideration for publication in IEEE Transactions on Consumer Electronics. This work presents a novel framework for robust RGB-Thermal (RGBT) object tracking, addressing critical challenges in consumer electronics applications such as smart security systems, autonomous navigation, and augmented reality devices.
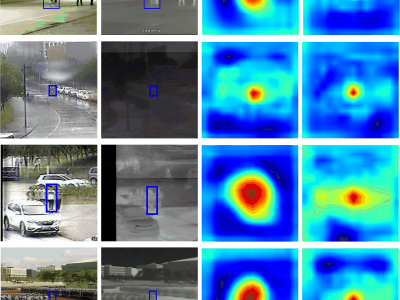
We are pleased to submit our manuscript entitled "Hetero-modal Template Guide Search Region for RGBT Tracking" for consideration for publication in IEEE Transactions on Consumer Electronics. This work presents a novel framework for robust RGB-Thermal (RGBT) object tracking, addressing critical challenges in consumer electronics applications such as smart security systems, autonomous navigation, and augmented reality devices.
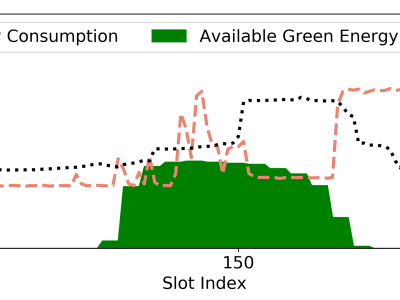
Data centers are increasingly adopting renewable energy sources to mitigate environmental impact and reduce operational costs. However, effectively optimizing energy costs remains challenging due to unpredictable workloads and fluctuating renewable energy availability. This paper introduces LOECM, a Lyapunov-driven online scheduling algorithm designed to minimize energy cost without relying on future information.

This dataset was synthesized through a large model. We deployed two large models, one playing the role of an elderly patient and the other playing the role of a nurse. The scenario we define is as follows: the patient lies on a deformed bed, conveying clear or unclear needs to the nurse. The nurse analyzes the patient's true needs based on their language, provides a humanized and personalized response to the patient, and issues control commands to the deformed bed. The dataset consists of two parts: patient statements - answers and patient statements - control commands.

This dataset comprises images of parts from real industrial scenarios and virtual reality environments. Real images are sourced from actual industrial settings, ensuring both authenticity and diversity, while virtual reality images, which make up approximately 11% of the dataset, are captured through precise 3D modeling. Approximately 30% of the part information was manually authored by industry experts, while the remaining 70% was generated by multimodal large models such as Wenxin Yiyan and GPT-4.