Other

This data content is the relevant data information in the paper "Research of the Scraper Bucket Motion Based on the Mathematical Model of Loader’s Working Device".
- Categories:
 81 Views
81 Views
nobody
- Categories:
95 Views
This is a compressed archive containing a Docker image with a software development kit (SDK) for HEROv2 (see https://github.com/pulp-platform/hero). This SDK currently contains:
- Categories:
111 Views
This dataset complies 172 chipless RFID measurements that have been reported in the literature from 2005-2022. The dataset contain the year, reading distance, frequency range, tag type, reader setup, and reference for each entry.
- Categories:
170 Views
The article presented a synthesis of expert opinions about open research remarked as a substantial influence on knowledge and innovation of concepts dissemination contained in published and unpublished manuscripts. The practise of open science reach increased in acceptance in recent years due to the challenging effort of the researchers who have written scientific articles.
- Categories:
140 Views
Task prioritization is one of the most researched areas in software development. Given the huge amount of papers written on the topic, it might be challenging for IT practitioners to find the most appropriate tools or methods developed to date to deal with this important issue. To overcome this problem, we conducted a systematic literature review. The main goal of this work is to review the current state of research and practice on task prioritization among IT practitioners and to individuate the most effective ranking tools and techniques used in the industry.
- Categories:
222 Views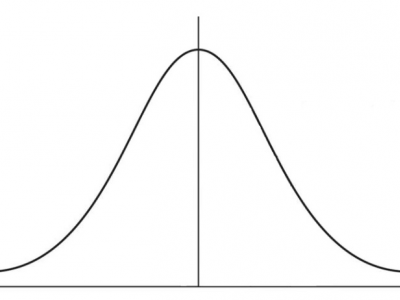
This dataset consists of a simulated normal distribution data having n = 500 data points and mean = 80 and standard deviation = 2.
- Categories:
1968 Views
This is the supplementary file of "Fast Algorithms for Exact IR Drop De-embedding in Analog Multiply-Accumulate Computing". Mathematical derivation and supporting data is provided.
- Categories:
71 Views
Dataset
- Categories:
122 Views
This is a dataset that contains 50,000 transactions and 13 features/columns, the data set is used to perform market basket analysis in association rule mining.
A random function was used during the generation and the function generates random numbers of 0's and 1's for all 13 features of each transaction.
The probability of generating a 1 is twice as high as 0, this way there will be a strong or almost-strong association between the features.
1 means an item was purchased by the user and 0 means the item was not purchased.
- Categories:
2632 Views