Machine Learning

Sign Language Recognition integrates computer vision and natural language processing to automatically interpret hand gestures and translate them into spoken or written Bengali. The primary goal is to bridge the communication gap between sign language users and non-users by recognizing gestures, movements, postures, and facial expressions that correspond to spoken language elements. Since hand gestures are the cornerstone of sign language communication, they play a pivotal role in improving the accuracy of sign language recognition systems.
- Categories:
 82 Views
82 Views
Abstract:
- Categories:
266 Views
SUNBURST Attack Dataset for Network Attack Detection
Overview:
The SUNBURST dataset is a unique and valuable resource for researchers studying network intrusion detection and prevention. This dataset provides real-world network traffic data related to SUNBURST, a sophisticated supply chain attack that exploited the SolarWinds Orion software. It focuses on the behavioral characteristics of the SUNBURST malware, enabling the development and evaluation of security mechanisms.
- Categories:
54 Views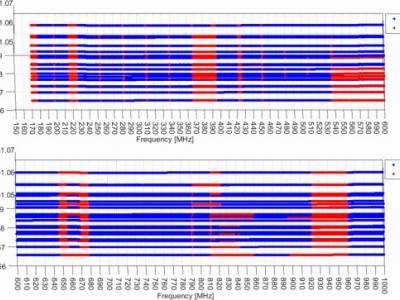
The dataset comprises the spectral density peak power levels from a spectrum survey in a rural area of Belgium. For the spectrum measurements we consider 21 locations of a rural scenario in Nevele, Belgium. This is a mostly flat area with detached isolated houses and farms. We defined a grid of different locations for measuring the peak signal levels [dBm] across the spectrum between 170 MHz and 1000 MHz, during a period of 0.5 h. The measurements across the different locations are not synchronized and, therefore not correlated in the time domain.
- Categories:
84 Views
Due to climate change, the Northwesterner Gilgit Baltistan's, Ghizer district is highly susceptible to glacial lake outburst floods (GLOFs). Nearly 24 GLOFs have occurred in this area in the last ∼200 years, demonstrating the growing recurrent nature of these incidents. Taking this into account, the assessment of risks associated with GLOFs was investigated in this study. All regional glacial lakes were identified in the first phase, and changes between 2000 and 2023 were mapped using moderate-resolution satellite images (Landsat).
- Categories:
60 Views
This dataset contains detailed player end-game statistics (e.g., number of kills) and in-game events (e.g., player kills) from all professional League of Legends matches held between September 15, 2019, and September 15, 2024. It encompasses a total of 37,388 matches across 392 tournaments, featuring 4,927 unique players. Matches come from all regions and tiers of play.
- Categories:
263 Views
The rapid growth of online shopping and e-commerce platforms has led to an explosion of product reviews. These reviews often contain valuable information about users’ opinions on various aspects of the products, including comparisons between different devices. Understanding comparative opinions from product reviews is crucial for manufacturers and consumers alike. Manufacturers can gain insights into the strengths and weaknesses of their products compared to competitors, while consumers can make more informed purchasing decisions based on these comparative insights.
- Categories:
20 Views
The Tunnel Cable Fire dataset is derived experimentally, this dataset contains images of cable flames at different stages, different cable layers, and different wind speeds, with a special focus on computer vision tasks such as fire detection and segmentation. These images have been enhanced with mosaic data for a total of 1812 datasets, including single and double layer cable fire images in the case of no wind and wind speed of 2.7m/s.
- Categories:
220 Views
AI was begun to increasingly part of EFL education introducing novelties, issues and opportunities. Current studies explore many possibilities, such as employing federated learning as a protection of data privacy and the implementation of ChatGPT in multilingual learning. This article offers comprehensive analysis of how AI could transform pedagogy, improve writing skills and motivate students through evaluating the novelty, existing voids, need, and implications of many the most promising studies.
- Categories:
135 Views
This dataset contains human motion data collected using inertial measurement units (IMUs), including accelerometer and gyroscope readings, from participants performing specific activities. The data was gathered under controlled conditions with verbal informed consent and includes diverse motion patterns that can be used for research in human activity recognition, wearable sensor applications, and machine learning algorithm development. Each sample is labeled and processed to ensure consistency, with raw and augmented data available for use.
- Categories:
28 Views