Non Line-of-Sight Perception Vehicular Camera Communication
- Citation Author(s):
-
Ashwin Ashok
 (Georgia State University)
Khadija Ashraf (Georgia State University)Vignesh VaradrajanMD Rashed RahmanRyan Walden
(Georgia State University)
Khadija Ashraf (Georgia State University)Vignesh VaradrajanMD Rashed RahmanRyan Walden - Submitted by:
- Ashwin Ashok
- Last updated:
- DOI:
- 10.21227/7s8r-8413
- Data Format:
- Research Article Link:
- Links:
 459 views
459 views
- Categories:
- Keywords:
Abstract
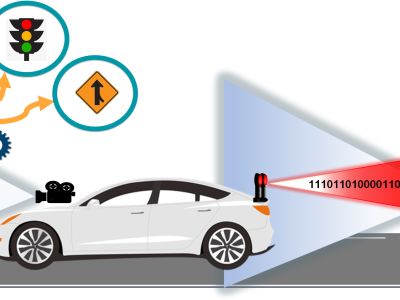
This dataset was used in our work "See-through a Vehicle: Augmenting Road Safety Information using Visual Perception and Camera Communication in Vehicles" published in the IEEE Transactions on Vehicular Technology (TVT). In this work, we present the design, implementation and evaluation of non-line-of-sight (NLOS) perception to achieve a virtual see-through functionality for road vehicles. In this system, a safety event, such as pedestrian crossing or traffic list status or vehicle merge, that are occluded to a driver due to another vehicle on the driving lane, are perceived and communicated by the occluding vehicle. Each vehicle is equipped with a camera, placed on the dashboard, that perceives the scene in a drivers view. This scene is analyzed and mapped into specific warning codes that are specific to a safety event, and communicated as short packets using visible light communication. The camera in the following vehicle captures this information and generates a recommendation for safety action to the driver by comparing the warning from the packet and from its own scene perception.
Instructions:
This project is an end-end python-3 application with a continuous loop captures and analyses 100 frames captured in a second to derive appropriate safety warnings.
Contact
Dr. Ashwin Ashok, Assistant Professor, Computer Science, Georgia State University
Collaborators
Project contents
This project contains 3 modules that should be run in parallel and interact with each other using 3 CSV files.
Modules
CSV Files
Usage :
Folling commands must be run in parallel. For more information on libraries needed for execution, see detailed sections below.
# Terminal 1 python3 non-line-of-sight-perception/VLC_project_flow.py zed # Terminal 2 python3 intelligent-vehicular-perception_ivp/src-code/ivp_impl.py # Terminal 3 python3 warning-transmission/send_bits_to_transmitter.py1. non-line-of-sight-perception : Object Detection and Scene Perception Module
This folder, For the YOLO-V3 training and inference: This project is a fork of public repository keras-yolo3. Refer the readme of that repository here. Relevant folders from this repository have been placed in training and configuration folders in this repository.
Installation of python libraries
Use the package manager pip to install foobar.
pip install opencv-python pip install tensorflow-gpu pip install Keras pip install PillowHardware requirements
- This code was tested on Jetson Xavier, but any GPU enabled machine should be sufficient.
- Zed Camera: Uses Zed camera to capture the images. (Requires GPU to operate at 100 fps).
- (Optional) the code can be modified as per the comments in file to use zed, 0 for the camera, or ' the video path' for mp4 or svo files)
Output
2. intelligent-vehicular-perception_ivp : Safety Message/Warning Mapping Module
This module is responsible for making intelligent recommendation to the driver as well as generating Safety Warnings for the following vehicles in the road. The module ouuputs with a fusion of Received Safety Warning through VLC channel and the vehicle's own Scene Perception Data.
Python Library Dependencies
- json
- operator
- csv
- enum
- fileinput
- re
Input
Output
The output is two-fold.
- packet.csv : Intelligent Recommendation to the Driver.
- receiver_action.csv : Generated Packet bits. Each Packet bits are logged into the 'packet.csv' file. This CSV files works as a queue. Every new packet logged here eventually gets transmitted by the VLC transmission module.
3. warning-transmission: Communication Module
Detailed transmitter notes including hardware requirement is present in transmitter_notes.txt
Python Library Dependencies
- serial
Input
- packet.csv : Intelligent Recommendation to the Driver.
Output
LED flashes high/low in correspondence to the packets in input file.
Dataset used for training the model
The dataset has been generated using Microsoft VoTT.
This is a "Brakelight" labelled dataset that can be used for training Brakelight detection models. The dataset contains brakelights labelled on images from
- experiments conducted in Atlanta, GA, USA by Dr. Ashwin Ashok's research group
- brake-light labelled images from Vehicle Rear Light Video Data*
*Reference : Cui, Z., Yang, S. W., & Tsai, H. M. (2015, September). A vision-based hierarchical framework for autonomous front-vehicle taillights detection and signal recognition. In Intelligent Transportation Systems (ITSC), 2015 IEEE 18th International Conference on (pp. 931-937). IEEE.
Labeled Dataset contains 1720 trained images as well a csv file that lists 4102 bounding boxes in the format : image | xmin | ymin | xmax | ymax | label
This can be further converted into the format as required by the training module using convert_dataset_for_training.py - (Replace annotations.txt with the Microsoft VoTT generated CSV) .
Acknowledgements
This work has been partially supported the US National Science Foundation (NSF) grants 1755925, 1929171 and 1901133.