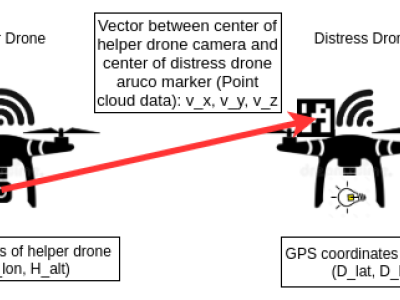
We design a solution to achieve coordinated localization between two unmanned aerial vehicles (UAVs) using radio and camera perception. We achieve the localization between the UAVs in the context of solving the problem of UAV Global Positioning System (GPS) failure or its unavailability. Our approach allows one UAV with a functional GPS unit to coordinate the localization of another UAV with a compromised or missing GPS system. Our solution for localization uses a sensor fusion and coordinated wireless communication approach.
- Categories: