Data_2
- Citation Author(s):
-
Anselme Herman EYELEKO

- Submitted by:
- Anselme Herman EYELEKO
- Last updated:
- DOI:
- 10.21227/wxey-x422
 369 views
369 views
- Categories:
- Keywords:
Abstract
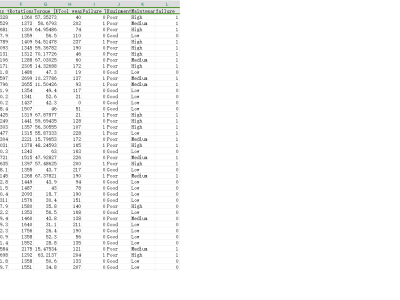
The Machine Failure Predictions Dataset (D_2) is a real-world dataset sourced from Kaggle, containing 10,000 records and 14 features pertinent to IIoT device performance and health status. The binary target feature, 'failure', indicates whether a device is functioning (0) or has failed (1). Predictor variables include telemetry readings and categorical features related to device operation and environment. Data preprocessing included aggregating features related to failure types and removing non-informative features such as Product ID. The initial dataset exhibited a significant class imbalance (3.39\% failure rate), which was rectified using the SMOTE algorithm, resulting in a balanced dataset. To further enhance modeling accuracy, 3,865 synthetic samples were generated through the Gretel.ai platform. D_2 is suitable for predictive modeling tasks in IIoT, allowing researchers to explore machine failure patterns and improve maintenance planning for industrial systems.
Instructions:
Instructions for Usage
Step 1: Dataset Access
To access the dataset, download it from IEEE DataPort. Ensure you have the appropriate permissions to access and use the dataset.
Step 2: Environment Setup
Before you begin working with the dataset, make sure that the necessary Python libraries are installed. These include:
pandas: for data manipulationnumpy: for numerical operationsimbalanced-learn: for SMOTE oversampling (if required)scikit-learn: for machine learning algorithms
pip install pandas numpy imbalanced-learn scikit-learn
Step 3: Data Loading
Load the dataset into your Python environment using the pandas library.
import pandas as pd
# Load the dataset
data = pd.read_csv('machine_failure_predictions.csv')
# Display the first few rows
print(data.head())
Step 4: Data Preprocessing
Since the dataset has undergone initial preprocessing, you may not need to perform extensive cleaning. However, it's advisable to review the dataset for missing values and correct data types.
# Check for missing values print(data.isnull().sum()) # Ensure that categorical variables are properly encoded data['failure'] = data['failure'].astype('category')Step 5: Feature Engineering
You can further engineer features based on the problem at hand. For example, you may want to convert time-based features (Hour, Day, Week) into cyclical features using sine and cosine transforms.
Step 6: Model Training
The target variable is failure (binary). You can use any machine learning model for binary classification (e.g., logistic regression, decision trees, random forests, etc.).
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score # Split the dataset into training and testing sets X = data.drop('failure', axis=1) y = data['failure'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Train a Random Forest model model = RandomForestClassifier() model.fit(X_train, y_train) # Make predictions y_pred = model.predict(X_test) # Evaluate the model print("Accuracy: ", accuracy_score(y_test, y_pred))
Step 7: Model Evaluation
Once the model is trained, evaluate its performance using metrics such as accuracy, precision, recall, and F1-score.
Step 8: Further Enhancements
You can experiment with other advanced techniques such as:
- Hyperparameter tuning using GridSearchCV.
- Handling class imbalance more effectively with techniques like SMOTE or cost-sensitive learning.
Use Cases
The Machine Failure Predictions Dataset (D_2) is ideal for:
- Predictive Maintenance: Identifying potential machine failures before they occur.
- Failure Pattern Analysis: Investigating factors leading to device failure.
- Operational Efficiency: Optimizing device usage and maintenance schedules.
- Anomaly Detection: Detecting abnormal device behavior based on sensor readings.


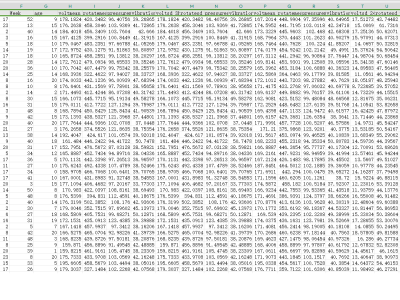





The Machine Failure Predictions Dataset (D_2) is a real-world dataset sourced from Kaggle, containing 10,000 records and 14 features pertinent to IIoT device performance and health status.