Data_1
- Citation Author(s):
-
Anselme Herman EYELEKO

- Submitted by:
- Anselme Herman EYELEKO
- Last updated:
- DOI:
- 10.21227/q7ae-2809
 283 views
283 views
- Categories:
- Keywords:
Abstract
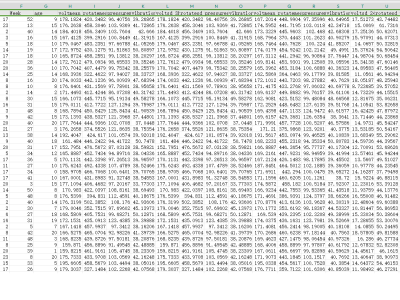
The PdM_telemetry Dataset (D_1) is a synthetic dataset designed to support predictive maintenance (PdM) research for IIoT (Industrial Internet of Things) devices by providing sensor-based telemetry data. This dataset initially comprises 97,210 records and 30 features, including a binary target feature, 'failure', which indicates whether a device will fail within the next 24 hours. The remaining features, such as device operational metrics and error counts, serve as predictors. Data preprocessing steps involved creating additional features from timestamp values and consolidating error count indicators to streamline analysis. Due to class imbalance, with only 0.70% of samples classified as failures, the dataset was balanced using the SMOTE algorithm to achieve equal representation of failure and non-failure cases. Further enhancement was performed by generating 38,085 synthetic samples using the Gretel.ai platform, enriching the dataset's variability and relevance for machine learning model training. This dataset is intended for developing and evaluating predictive models for IIoT device failure, contributing to more accurate and timely maintenance interventions.
Instructions:
Data Loading and Preparation
To begin using the PdM_telemetry dataset:
1. Download and Import the Dataset: Load the dataset using Python or any compatible data analysis library.
```python
import pandas as pd
data = pd.read_csv("path_to/PdM_telemetry_dataset.csv")
```
2. Initial Data Inspection: Check the first few records to understand its structure.
```python
print(data.head())
```
Steps for Data Analysis
1. Exploratory Data Analysis (EDA): Perform EDA to identify patterns, distributions, and relationships among features.
- Example: Plotting `failure` rates over time using `datetime` features (`Day`, `Hour`, `Week`).
- Calculate summary statistics to inspect central tendencies and variances.
2. Outlier Detection: For training models, consider using outlier detection techniques to refine data. Options include techniques such as NFOM (Novel Outlier Filtration Method) which this dataset was designed to evaluate.
3. Predictive Model Development:
- Use the balanced dataset to develop machine learning models (e.g., Logistic Regression, Random Forest, SVM) to predict failures.
- Split data into training and test sets.
- Standardize or normalize the sensor features for optimal model performance.
```python
from sklearn.model_selection import train_test_split
X = data.drop(columns=['failure'])
y = data['failure']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
```
4. Evaluating Model Performance:
- Evaluate models with metrics such as accuracy, precision, recall, and F1-score.
- Run cross-validation to ensure model robustness, especially due to the dataset’s synthetic and balanced nature.
Suggested Use Cases
- Predictive Maintenance: Develop models for preemptively identifying machines likely to fail, thereby optimizing maintenance schedules and reducing downtime.
- Failure Analysis: Conduct root cause analysis by examining sensor data patterns and failure types to identify underlying causes of device malfunctions.
- Feature Engineering: Create additional temporal and operational features from `datetime` and categorical fields to improve the predictive performance of models.
Additional Resources
- SMOTE: For details on the SMOTE balancing technique, refer to [imbalanced-learn documentation](https://pypi.org/project/imbalanced-learn/).
- Gretel.ai: For information on synthetic data generation, see [Gretel.ai](https://www.gretel.ai).


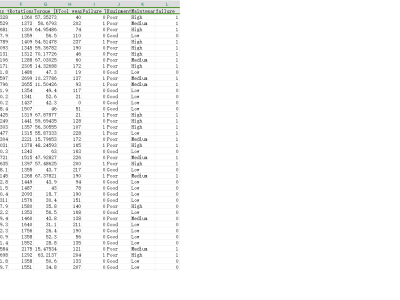





The PdM_telemetry Dataset (D_1) is a synthetic dataset designed to support predictive maintenance (PdM) research for IIoT (Industrial Internet of Things) devices by providing sensor-based telemetry data.