deepfake detection
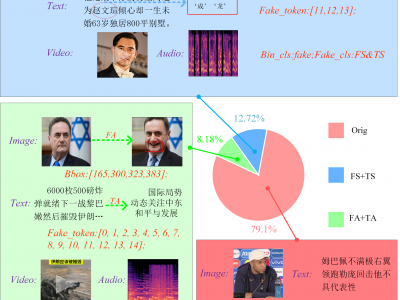
DLSF is the first dedicated dataset for Text-Image Synchronization Forgery (TISF) in multimodal media. The source data for this dataset is scraped from the Chinese news aggregation platform, Toutiao. This dataset includes extensive text, image, and audio-video data from news articles involving politicians and celebrities, featuring samples of both entity-level and attribute-level TISF. It provides comprehensive annotations, including labels for text-image authenticity, types of TISF, image forgery regions, and text forgery tokens.
- Categories:
 111 Views
111 Views
Introduced here is the Extended-Length Audio Dataset for Synthetic Voice Detection and Speaker Recognition (ELAD-SVDSR), a resource designed to advance research in synthetic voice (DeepFake) detection and automatic speaker recognition (ASR). It features around 45-minute audio recordings from 36 participants, each of whom read aloud different newspaper articles during controlled sessions, captured with five different high-quality microphones. Synthetic voices generated from 20 subjects of this dataset using open-source and commercial software are also included.
- Categories:
114 Views
Recent advances in generative visual content have led to a quantum leap in the quality of artificially generated Deepfake content. Especially, diffusion models are causing growing concerns among communities due to their ever-increasing realism. However, quantifying the realism of generated content is still challenging. Existing evaluation metrics, such as Inception Score and Fréchet inception distance, fall short on benchmarking diffusion models due to the versatility of the generated images.
- Categories:
174 Views