Artificial Intelligence

The Forbes 2022 Billionaires List dataset contains information about the world's wealthiest individuals, including their net worth, industry, country, and key business ventures. The dataset provides structured details such as rankings, company associations, and financial status, making it useful for various NLP tasks like table-to-text generation, entity recognition, and financial analysis.
- Categories:
 44 Views
44 Views
To establish a versatile RSFM adaptable to diverse tasks, RingMoE requires a comprehensive and diverse pre-training dataset that accounts for significant variations in imaging modalities, spatial resolutions, temporal dynamics, geographic regions, and scene complexities. To meet this challenge, we curate RingMOSS, a large-scale multi-modal RS dataset comprising 400 million images from nine satellite platforms, covering a broad spectrum of Earth observation scenarios.
- Categories:
25 Views
This dataset contains texture maps, flow field data, and aerodynamic pressure data on the surface of five different vehicle profiles under specific flight conditions, and is suitable for research in aerospace engineering, hydrodynamics, and related fields. The dataset covers the altitude range from 3000 to 4000 meters and the Mach number range from 2.0 to 2.75.
- Categories:
243 Views
This wind speed dataset is voluntarily made public by me, with the aim of supporting academic research, data analysis, and further exploration in related fields. The dataset strictly adheres to relevant safety protocols, ensuring that all data usage and dissemination comply with safety requirements and respect applicable laws and regulations. By making this dataset public, I hope to provide a reliable resource for the academic community, researchers, and other institutions in need, to foster more research and technological development based on wind speed.
- Categories:
10 Views
This dataset integrates textual, financial, and macroeconomic indicators to support research on bank failure prediction and financial distress forecasting in Vietnam. It includes financial news from the BKAI News Corpus Dataset (2009–2023) and financial crisis data from "A Dataset for the Vietnamese Banking System (2002–2021)" (Tu Le et al., 2022), covering crisis-related events such as restructuring, special control, mergers, and acquisitions.
- Categories:
52 Views
The Semantic Highlight Mask Dataset holds significant importance in the field of computer vision, particularly for tasks such as object detection, image segmentation, and scene understanding. This paper proposes a novel Semantic Highlight Mask Dataset designed to support high-precision semantic segmentation and emphasize key regions in images. The dataset encompasses a diverse range of image categories, with finely annotated highlight masks assigning semantic labels and saliency weights to each pixel.
- Categories:
10 Views
The Semantic Highlight Mask Dataset holds significant importance in the field of computer vision, particularly for tasks such as object detection, image segmentation, and scene understanding. This paper proposes a novel Semantic Highlight Mask Dataset designed to support high-precision semantic segmentation and emphasize key regions in images. The dataset encompasses a diverse range of image categories, with finely annotated highlight masks assigning semantic labels and saliency weights to each pixel.
- Categories:
6 Views
The dataset of the DGCMF-MSN, where includes 1,020 drug entities, 5,598 standardized side effects, and 133,750 validated positive association samples. Additionally, the feature-engineered data derived from the three-modal data of these 1,020 drugs are also included. Drug-se_matrix.txt is a matrix of drug-side effect associations. Drugs.smiles contains feature engineering results derived from SMILES representations. Drugs.fpt contains molecular fingerprint feature engineering results.
- Categories:
9 Views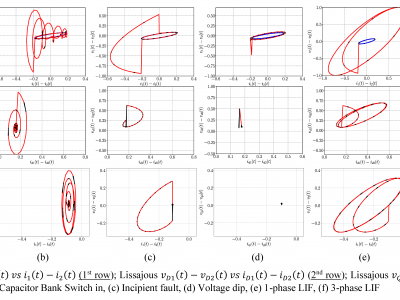
This dataset supports the research paper "Synchronized Waveform Monitoring Unit Application: Lissajous DQ Curve to Improve Situational Awareness in Power Distribution Networks". It contains electromagnetic transient (EMT) simulation results from the IEEE 33-bus distribution system, including:
- Categories:
153 Views
This dataset comprises a comprehensive collection of educational courses, each characterized by several key attributes: interests, title, description, category, level, past experience, and rating.
- Categories:
17 Views