Artificial Intelligence

The Travel Recommendation Dataset is a comprehensive dataset designed for building and evaluating conversational recommendation systems in the travel domain. It includes detailed information about users, destinations, and ratings, enabling researchers and developers to create personalized travel recommendation models. The dataset supports use cases such as personalizing travel recommendations, analyzing user behavior, and training machine learning models for recommendation tasks.
- Categories:
 7 Views
7 Views
This dataset compilation brings together four significant traffic network datasets from California's transportation monitoring systems: METR-LA, PEMS-BAY, PEMS04, and PEMS08. The METR-LA dataset is collected from the traffic monitoring system in the Los Angeles area and records detailed traffic speed data. The PEMS-BAY, PEMS04, and PEMS08 datasets originate from the California Department of Transportation (Caltrans) Performance Measurement System, with PEMS-BAY recording traffic speed data, while PEMS04 and PEMS08 record traffic flow data.
- Categories:
5 Views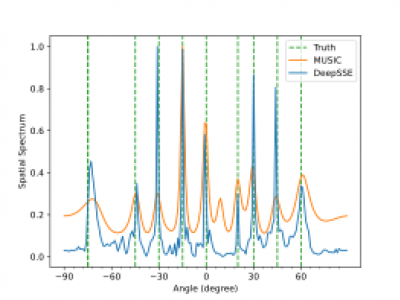
Dataset for multiple signal DOA estmation. This the original dataset used in our research. we consider a ULA with M = 16 antenna elements spaced at half-wavelength distance (l = λ/2). We consider narrowband, non-coherent signals with different intermediate frequencies (IF) transmitted from different sources. The signals are sampled at the intermediate frequency with a sampling frequency of 2.5MHz and 300 sample points. Then we simulate the array received signal according to signal model (1) at different SNRs of {-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5} dB.
- Categories:
43 Views
We evaluate the proposed FSDUF model on three publicly available social media benchmark datasets: Weibo {jin2017multimodal}, Twitter {boididou2015verifying}, and Pheme {zubiaga2017exploiting}.
- Categories:
11 Views
The NYUD V2 data set is comprised of video sequences from a variety of indoor scenes as recorded by both the RGB and Depth cameras from the Microsoft Kinect. It features: 1449 densely labeled pairs of aligned RGB and depth images 464 new scenes taken from 3 cities, 407,024 new unlabeled frames
- Categories:
18 Views
To generate the training and validation datasets, the fullwave electromagnetic solver FEKO is utilized. The phase of the reference antenna (Antenna 1) is fixed at 0°, while the phases of the other three antennas are varied in 30° steps within the range [0◦ , 360◦ ]. This results in 13×13×13 = 2197 distinct phase combinations. For each combination, the farfield radiation intensities are extracted on the XOY, YOZ, and XOZ planes, yielding a total of 2197 × 3 data samples. For testing, 343 new phase combinations are generated within the interval [15◦ , 195◦ ] using 30° steps (i.e., 7×7×7).
- Categories:
66 Views
To generate the training and validation datasets, the fullwave electromagnetic solver FEKO is utilized. The phase of the reference antenna (Antenna 1) is fixed at 0°, while the phases of the other three antennas are varied in 30° steps within the range [0◦ , 360◦ ]. This results in 13×13×13 = 2197 distinct phase combinations. For each combination, the farfield radiation intensities are extracted on the XOY, YOZ, and XOZ planes, yielding a total of 2197 × 3 data samples. For testing, 343 new phase combinations are generated within the interval [15◦ , 195◦ ] using 30° steps (i.e., 7×7×7).
- Categories:
34 Views
Bitcoin(₿) is a cryptocurrency invented in 2008 by an unknown person or group of people using the pseudonym Satoshi Nakamoto. The currency began use in 2009 when its implementation was released as open-source software.
- Categories:
68 Views
This dataset comprises vibration signals collected from bearing test rigs under both healthy and faulty conditions, designed to support research in fault diagnosis and out-of-distribution (OOD) detection. The data includes:
-
CWRU Dataset: Signals from the Case Western Reserve University bearing test platform, sampled at 12 kHz, covering normal operation and three fault types (inner race, outer race, and rolling element faults) with varying severities (0.007–0.021 inches). OOD samples are explicitly labeled for validation.
- Categories:
19 Views
Vertical Federated Learning (VFL) enables multiple organizations to collaboratively train machine learning models without sharing raw data, particularly suited for tabular datasets with aligned sample IDs but disjoint feature spaces. Despite its growing relevance in privacy-sensitive sectors such as finance and healthcare, publicly available benchmarks for VFL on tabular data remain limited. This paper introduces and categorizes a collection of real-world tabular datasets tailored for VFL research, highlighting their feature distribution, domain applicability, and security relevance.
- Categories:
7 Views