Telugu Handwritten Character Dataset
- Citation Author(s):
-
Muni Sekhar Velpuru
 (Vardhaman College of Engineering)
Tejasree G (Vardhaman College of Engineering)Ravi Kumar M (JBREC)
(Vardhaman College of Engineering)
Tejasree G (Vardhaman College of Engineering)Ravi Kumar M (JBREC) - Submitted by:
- muni sekhar velpuru
- Last updated:
- DOI:
- 10.21227/mw6a-d662
- Data Format:
 5070 views
5070 views
- Categories:
- Keywords:
Abstract
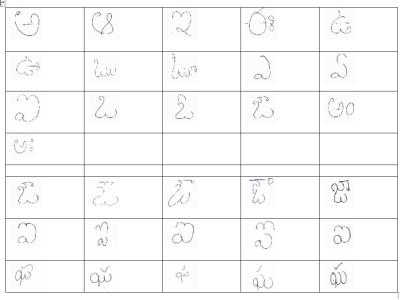
The dataset consists all the Telugu characters that contains Vowels, Consonants and combine characters such as Othulu (Consonant-Consonant) and Guninthamulu (Consonant-Volwels). The main objective of this dataset to recognize handwritten Telugu characters, from that convert handwritten document into editable electronic copy. There is a significant difference between Indian literature and English literature, i.e., if we see English literature only 26 Characters, but where in Telugu total number of characters are 1,924 (Achulu (Vowels)- 16, Hallulu (consonants)- 36, Othulu – 36 and Guninthamulu – 34*16=544). Hence, problem of recognition of Telugu characters are complex in compare to English. Furthermore, no dataset of Telugu characters that covers all characters in Telugu literature and even the worldwide encoding standard “Unicode” have not covering all Alphabet in Telugu. The objective of this work is to present a Handwritten Telugu character dataset with all Telugu Alphabets, assigning unique label to each character from there assign ‘Unicode’ to each label. If we could bring all Telugu and other Indian language characters into ‘Unicode’, it will resolve compatibility issues of all major Operating Systems and Word Processors. The dataset is designed to recognize all short of handwriting styles. Hence, we create dataset from different distinct writers in that some are from schools (under 15 years), some are from above 45 years and some are engineering graduates at the age between 18-24. Moreover, we gave unique labels for each character in Telugu literature. Hence, these labels are also support other Indian languages because of similarity in Phonics.
Instructions:
All the images are in the same size and all images are scanned by scanner and segmented manually and all images are jpeg images.
Acknowledgement:
The work is carried out under Collaborative Research Project Sponsored by JNTU Hyderabad, India. The project file no. JNTUH/TEQIP-III/CRS/2019/CSE/12 and Titled as "Deep Learning Aided-OCR for Handwritten Telugu Character".






