First Name
muni sekhar
Last Name
velpuru
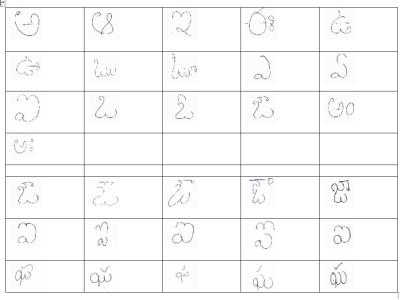
The dataset consists all the Telugu characters that contains Vowels, Consonants and combine characters such as Othulu (Consonant-Consonant) and Guninthamulu (Consonant-Volwels). The main objective of this dataset to recognize handwritten Telugu characters, from that convert handwritten document into editable electronic copy.