Memory Dumps of Virtual Machines for Cloud Forensics
- Citation Author(s):
-
Prasad Purnaye
 (Researcher)
Vrushali Kulkarni
(Professor)
(Researcher)
Vrushali Kulkarni
(Professor)
- Submitted by:
- Prasad Purnaye
- Last updated:
- DOI:
- 10.21227/ft6c-2915
- Data Format:
- Research Article Link:
- Links:
 1493 views
1493 views
- Categories:
- Keywords:
Abstract
The dataset contains memory dump data which is generated continuously. For the experiment we carried out, we implemented the volatile data dump module which generated around 360 VM memory dump images of average size 800Mb each (Total 288GB). These data files are compressed using gzip utility. Further zipped to 79.5GB one single file of memory evidence.
Out of these preserved and stored memory dump dataset, 79 files of size 17.3GB were generated during the attack. This means the data 21.76% of data (in size) is potential evidence.
These statistics only depicts the current scenario of the simulation and subject to change as per the attack duration.
Instructions:
There are total 360 gzip files in the datasets. Each of the gzip file can be extracted to a *.mem file. Filename of which represented in VMID_LASTPOLL.mem format. For example if memory dump is taken at 07:20:00AM 15 Dec 2020 (IST) would be =>1608016800 and the ID of the VM is 4 then the filename would be "4_1608016800.mem". The 256-bit SHA hash is also stored in the supporting file named memrepo.zip. For smaller version of the database you can contact the author at prasad.purnaye@mitwpu.edu.in



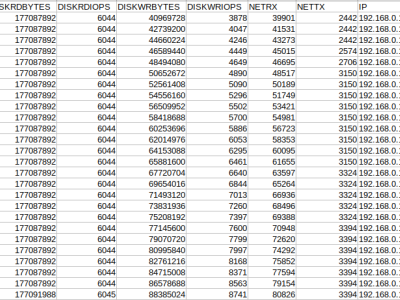



In reply to Hi...can i please know the by payal saluja